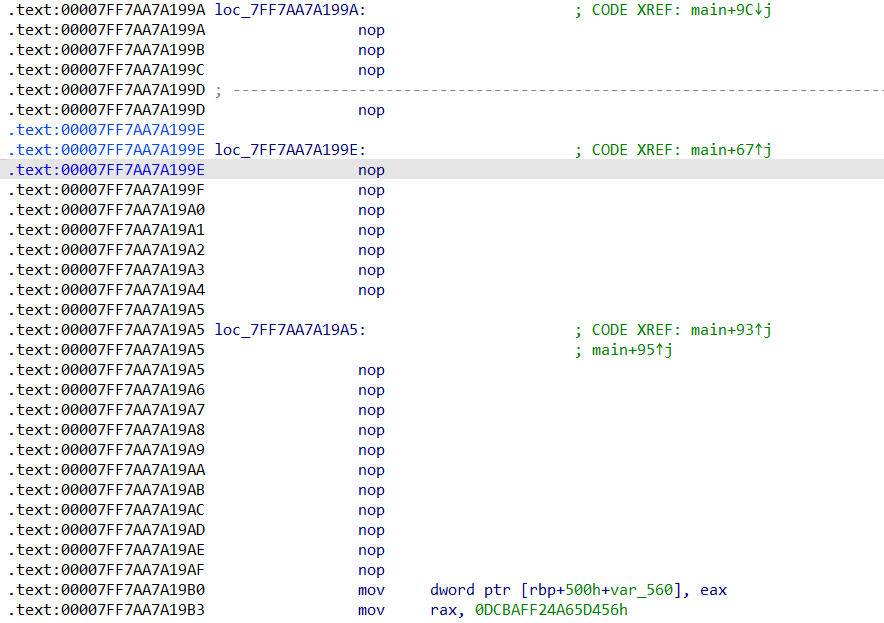
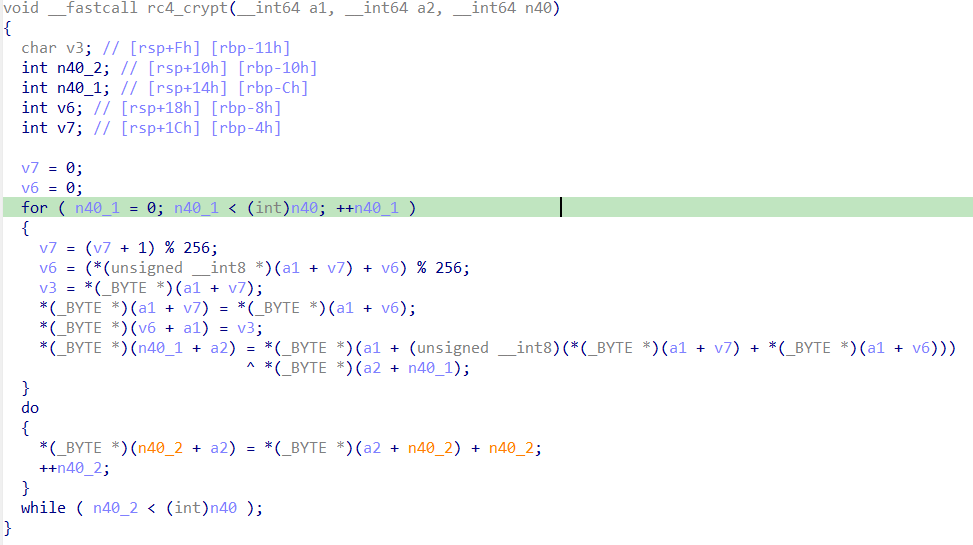
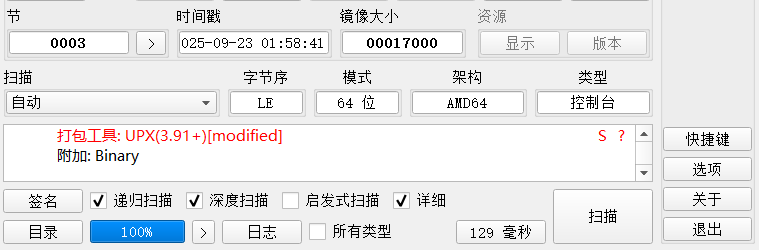
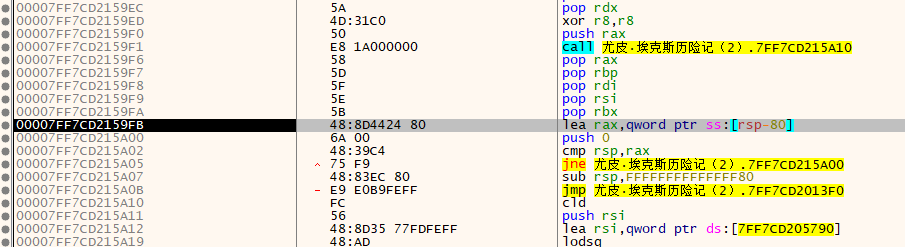
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
| #!/usr/bin/env python3
# -*- coding: utf-8 -*-
import struct
from typing import List, Tuple
C1 = 1071031968 # 0x3FCCE420
C2 = 0xFD714A3E
C3 = 0x73F96656
C4 = 391575037 # 0x1753D7FD
C5 = 0x724A13FF
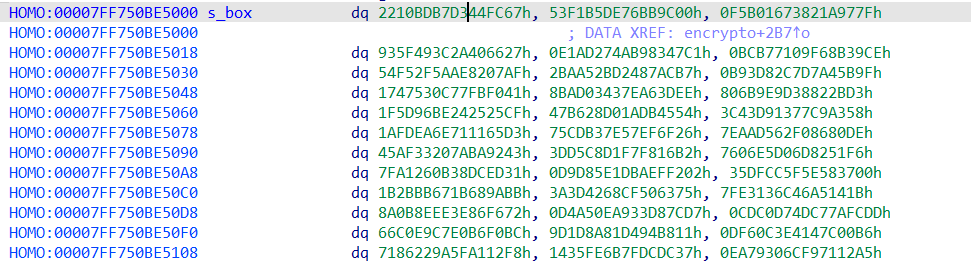
S_BOX_BYTES = bytes([
0x67, 0xfc, 0x44, 0xd3, 0xb7, 0xbd, 0x10, 0x22,
0x00, 0x9c, 0xbb, 0x76, 0xde, 0xb5, 0xf1, 0x53,
0x7f, 0x97, 0x1a, 0x82, 0x73, 0x16, 0xb0, 0xf5,
0x27, 0x66, 0x40, 0x2a, 0x3c, 0x49, 0x5f, 0x93,
0xc1, 0x47, 0x83, 0xb9, 0x4a, 0x27, 0xad, 0xe1,
0xce, 0x39, 0x8b, 0xf6, 0x09, 0x71, 0xb7, 0xbc,
0xaf, 0x07, 0x82, 0xae, 0x5a, 0x2f, 0xf5, 0x54,
0xb7, 0xac, 0x87, 0x24, 0xbd, 0x52, 0xaa, 0x2b,
0x9f, 0x5b, 0xa4, 0xd7, 0xc7, 0x82, 0x3d, 0xb9,
0x41, 0xf0, 0xfb, 0x77, 0x0c, 0x53, 0x47, 0x17,
0xee, 0x3d, 0xa6, 0x7e, 0x43, 0x03, 0xad, 0x8b,
0xd3, 0x2b, 0x82, 0x38, 0x9d, 0x9e, 0x6b, 0x80,
0xcf, 0x25, 0x25, 0x24, 0xbe, 0x96, 0x5d, 0x1f,
0x54, 0x45, 0xdb, 0x1a, 0xd0, 0x28, 0xb6, 0x47,
0x58, 0xa3, 0xc9, 0x77, 0x13, 0xd9, 0x43, 0x3c,
0xd3, 0x65, 0x11, 0x71, 0x6e, 0xea, 0xfd, 0x1a,
0x26, 0x6f, 0xef, 0x57, 0x7e, 0xb3, 0xcd, 0x75,
0xde, 0x80, 0x86, 0xf0, 0x62, 0xd5, 0xaa, 0x7e,
0x43, 0x92, 0xba, 0x7a, 0x20, 0x33, 0xaf, 0x45,
0xb2, 0x16, 0xf8, 0xf7, 0xd1, 0xc8, 0xd5, 0x3d,
0xf6, 0x51, 0x82, 0x6d, 0xd0, 0xe5, 0x06, 0x76,
0x31, 0xed, 0xdc, 0x38, 0x0b, 0x26, 0xa1, 0x7f,
0x02, 0xf2, 0xef, 0xba, 0x1d, 0x5e, 0xd8, 0xd9,
0x00, 0x37, 0x58, 0x5e, 0x5f, 0xcc, 0xdf, 0x35,
0xbb, 0x9a, 0x68, 0x1b, 0x67, 0xbb, 0x2b, 0x1b,
0x75, 0x63, 0x50, 0xcf, 0x68, 0x42, 0x3d, 0x3a,
0x1b, 0x14, 0xa5, 0x46, 0x6c, 0x13, 0xe3, 0x7f,
0x72, 0xf6, 0x86, 0x3e, 0xee, 0x8e, 0x0b, 0x8a,
0xd7, 0x7c, 0xd8, 0x33, 0xa9, 0x0e, 0xa5, 0xd4,
0xdd, 0xfc, 0x7a, 0xc7, 0x4d, 0xd7, 0xc0, 0xcd,
0xbc, 0xf0, 0xb6, 0xe0, 0xc7, 0xe9, 0xc0, 0x66,
0x11, 0xb8, 0x94, 0xd4, 0x81, 0x8a, 0x1d, 0x9d,
0xb6, 0x00, 0x7c, 0x14, 0xe4, 0xc3, 0x60, 0xdf,
0xf8, 0x12, 0xa1, 0x5f, 0x9a, 0x22, 0x86, 0x71,
0x37, 0xdc, 0xdc, 0x7f, 0x6b, 0xfe, 0x35, 0x14,
0xa5, 0x12, 0x71, 0xf9, 0x6c, 0x30, 0x79, 0xea
])
# 转换为DWORD数组(小端序)
S_BOX = [struct.unpack('<I', S_BOX_BYTES[i:i+4])[0] for i in range(0, len(S_BOX_BYTES), 4)]
IV_BYTES = bytes([0xb2, 0xe8, 0x87, 0xbe, 0x92, 0xf3, 0xe9, 0x88, 0xc3, 0x40, 0xfb, 0x16])
IV = [struct.unpack('<I', IV_BYTES[i:i+4])[0] for i in range(0, len(IV_BYTES), 4)]
ENC_DATA = bytes([
0xc7, 0xc9, 0x4c, 0x95, 0x6f, 0xbf, 0xc9, 0xf4,
0xc4, 0x86, 0xa4, 0x20, 0x57, 0x55, 0x6b, 0xe2,
0xea, 0xdc, 0xb7, 0x3f, 0x9c, 0x42, 0x1e, 0xe1,
0x72, 0x82, 0x0d, 0x93, 0xb3, 0xf9, 0xd0, 0x35,
0x93, 0x70, 0xff, 0x44, 0x72, 0x61, 0x55, 0xf8,
0xec, 0xda, 0xfb, 0x6e, 0xa8, 0xa6, 0xcb, 0x9e
])
def f_function(x: int) -> int:
"""
F函数 (sub_7FF750BE1450)
逆向伪代码:
return ((((a1 + C1) ^ C2) + C3) ^ C4) - C5
"""
x = (x + C1) & 0xFFFFFFFF
x = (x ^ C2) & 0xFFFFFFFF
x = (x + C3) & 0xFFFFFFFF
x = (x ^ C4) & 0xFFFFFFFF
x = (x - C5) & 0xFFFFFFFF
return x
def f_inverse(y: int) -> int:
"""
F函数的逆函数
逆向操作序列(从后往前):
"""
y = (y + C5) & 0xFFFFFFFF
y = (y ^ C4) & 0xFFFFFFFF
y = (y - C3) & 0xFFFFFFFF
y = (y ^ C2) & 0xFFFFFFFF
y = (y - C1) & 0xFFFFFFFF
return y
def bytes_to_dwords(data: bytes) -> List[int]:
"""将字节数组转换为DWORD数组(小端序)"""
dwords = []
for i in range(0, len(data), 4):
if i + 4 <= len(data):
dwords.append(struct.unpack('<I', data[i:i+4])[0])
else:
remaining = data[i:] + b'\x00' * (4 - len(data[i:]))
dwords.append(struct.unpack('<I', remaining)[0])
return dwords
def dwords_to_bytes(dwords: List[int], length: int) -> bytes:
"""将DWORD数组转换回字节数组"""
result = b''
for dword in dwords:
result += struct.pack('<I', dword)
return result[:length]
def decrypt_block(enc_block: Tuple[int, int, int], s_box: List[int]) -> Tuple[int, int, int]:
"""
解密一个3-DWORD块(逆向72轮Feistel结构)
加密轮函数(从IDA分析):
for n71 = 0 to 71:
v3 = size_[n71]
temp = (size_[n71+2] ^ size_[n71+1]) ^ s_box[n71]
v4 = v3 ^ F(temp)
size_[n71+3] = F(v4)
解密轮函数(逆向):
for n71 = 71 down to 0:
temp = (size_[n71+2] ^ size_[n71+1]) ^ s_box[n71]
size_[n71] = F_inv(size_[n71+3]) ^ F(temp)
参数:
enc_block: 加密后的3个DWORD (size_[72], size_[73], size_[74])
s_box: S盒数组
返回:
解密后的3个DWORD (size_[0], size_[1], size_[2])
"""
size = [0] * 75
# 最后3个值是已知的(加密后的值)
size[72], size[73], size[74] = enc_block
# 从第71轮逆向到第0轮
for i in range(71, -1, -1):
temp = (size[i+2] ^ size[i+1]) ^ s_box[i]
size[i] = (f_inverse(size[i+3]) ^ f_function(temp)) & 0xFFFFFFFF
return (size[0], size[1], size[2])
def decrypt_full(enc_data: bytes, s_box: List[int], iv: List[int]) -> bytes:
# 步骤1: 转换为DWORD数组
enc_dwords = bytes_to_dwords(enc_data)
count = len(enc_dwords)
print(f"[*] 加密数据: {count} DWORDs")
# 步骤2: 逆向CBC模式
# CBC模式:C[i] = E(P[i] XOR C[i-1]), C[-1] = IV
# 解密:P[i] = D(C[i]) XOR C[i-1]
cbc_reversed = enc_dwords.copy()
# 从后往前,每个DWORD与前面第3个DWORD异或(因为块大小是3)
for i in range(count - 1, 2, -1):
cbc_reversed[i] = (cbc_reversed[i] ^ cbc_reversed[i - 3]) & 0xFFFFFFFF
# 前3个与IV异或
for i in range(min(3, count)):
cbc_reversed[i] = (cbc_reversed[i] ^ iv[i]) & 0xFFFFFFFF
print(f"[*] CBC逆向完成")
# 步骤3: 对每个3-DWORD块进行解密
decrypted = []
num_blocks = (count + 2) // 3
for i in range(num_blocks):
# 提取一个块(3个DWORD)
block = []
for j in range(3):
idx = i * 3 + j
if idx < count:
block.append(cbc_reversed[idx])
else:
block.append(0)
# 解密这个块
dec_block = decrypt_block(tuple(block), s_box)
decrypted.extend(dec_block)
print(f"[*] 块解密完成: {num_blocks} 块")
# 步骤4: 转换回字节
result = dwords_to_bytes(decrypted, len(enc_data))
return result
def main():
print("=" * 70)
print("尤皮·埃克斯历险记(2) - 逆向解密脚本")
print("=" * 70)
print()
print(f"[*] S盒: {len(S_BOX)} DWORDs")
print(f"[*] IV: {[hex(x) for x in IV]}")
print(f"[*] 密文长度: {len(ENC_DATA)} 字节")
print()
# 执行解密
plain = decrypt_full(ENC_DATA, S_BOX, IV)
print()
print("=" * 70)
print("解密结果")
print("=" * 70)
print()
# 转换为DWORD查看
plain_dwords = bytes_to_dwords(plain)
print(f"解密得到的DWORD ({len(plain_dwords)}个):")
for i, dw in enumerate(plain_dwords):
print(f" [{i:02d}] 0x{dw:08X}")
# 关键发现:每个DWORD的第0个字节包含flag
print()
print("=" * 70)
print("FLAG提取")
print("=" * 70)
print()
print("[*] 提取每个DWORD的各字节位置:")
byte_positions = [[], [], [], []]
for dw in plain_dwords:
byte_positions[0].append((dw >> 0) & 0xFF)
byte_positions[1].append((dw >> 8) & 0xFF)
byte_positions[2].append((dw >> 16) & 0xFF)
byte_positions[3].append((dw >> 24) & 0xFF)
for i, pos_bytes in enumerate(byte_positions):
b = bytes(pos_bytes)
printable = ''.join(chr(x) if 32 <= x < 127 else '.' for x in pos_bytes)
printable_count = sum(1 for x in b if 32 <= x < 127)
print(f" 位置{i}: {b.hex()} ({printable}) [{printable_count}/12可打印]")
# 提取FLAG - 方法1:每个DWORD的第0字节
flag_bytes_pos0 = bytes(byte_positions[0])
# 提取FLAG - 方法2:直接转换DWORD为字符串(小端序)
print()
print("[*] 直接从DWORD转换(小端序):")
flag_from_dwords = b''
for dw in plain_dwords:
flag_from_dwords += struct.pack('<I', dw)
print(f" 十六进制: {flag_from_dwords.hex()}")
try:
flag_direct = flag_from_dwords.decode('ascii')
print(f" ASCII: {flag_direct}")
except:
printable = ''.join(chr(b) if 32 <= b < 127 else '.' for b in flag_from_dwords)
print(f" 可打印: {printable}")
print()
print("=" * 70)
# 检查哪个是正确的flag
if flag_from_dwords[:5] == b'flag{':
print(f"[+] FLAG: {flag_from_dwords.decode('ascii')}")
elif flag_bytes_pos0[:5] == b'flag{':
try:
print(f"[+] FLAG: {flag_bytes_pos0.decode('ascii')}")
except:
printable = ''.join(chr(b) if 32 <= b < 127 else '.' for b in flag_bytes_pos0)
print(f"[+] FLAG (可打印字符): {printable}")
else:
print(f"[+] FLAG候选1 (直接转换): {flag_from_dwords.decode('ascii', errors='replace')}")
print(f"[+] FLAG候选2 (位置0): {flag_bytes_pos0.hex()}")
print("=" * 70)
if __name__ == "__main__":
main()
|